

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

# invisible
#from IPython.display import HTML, display
import numpy as np
np.core.arrayprint._line_width = 65
In unserem Python-Tutorial haben wir viele Operatoren gesehen. Darüber haben wir dort gelernt, wie man Operatoren mittels "magischer Funktionen" überladen kann. Wir wissen nun, dass wir beispielsweise das "+"-Operatorzeichen nutzen können, um numerische Werte zu addieren oder Strings und Listen zu konkatenieren:
42 + 5
"Python ist eine der besten " + "oder die beste Programmiersprache!"
In dieser Einführung werden wir nun lernen, dass auch in NumPy die Operatorzeichen entsprechend überladen sind, sodass wir sie in "natürlicher" Weise nutzen können.
So können wir beispielsweise Skalare zu Arrays addieren, d.h. der Skalar wird zu jeder Komponente addiert. Das Gleiche ist möglich für die Subtraktion, die Division, die Multiplikation und sogar für Funktionen wie Sinus, Kosinus und so weiter.
Selbstverständlich können wir auch all diese Operatoren auf zwei Arrays anwenden.
Operatoren und Skalare
Beginnen wir mit der skalaren Addition:
# prog4book
import numpy as np
kalorientabelle = np.array([30, 52, 88, 36, 86,
160, 375, 115, 43, 71])
jouletabelle = kalorientabelle * 4.1868
print(jouletabelle)
# prog4book
jouletabelle = np.round((kalorientabelle * 4.1868), 0)
print(jouletabelle)
# prog4book
jouletabelle = jouletabelle.astype(np.int16)
print(jouletabelle)
# prog4web
import numpy as np
lst = [2, 3, 7.9, 3.3, 6.9, 0.11, 10.3, 12.9]
v = np.array(lst)
print(v + 2)
Multiplikation, Subtraktion, Division und Exponentiation sind ebenso leicht zu bewerkstelligen wie die vorige Addition:
# prog4book
verzehr_in_gramm = np.array([240, 95, 135, 120, 200,
160, 290, 450, 500, 0])
verzehr_in_kg = verzehr_in_gramm / 1000
print(verzehr_in_kg)
# Diät, 10 % weniger essen:
reduzierter_verzehr_in_kg = verzehr_in_kg * 0.9
print(reduzierter_verzehr_in_kg)
# prog4web
print(v * 2.2)
# prog4web
print(v - 1.38)
# prog4web
print(v ** 2)
print(v ** 1.5)
Wir hatten dieses Beispiel mit einer Liste lst begonnen. Wie kann man zu einer numerischen Liste einen Skalar addieren, so wie wir es mit dem Array v getan hatten?
Zu diesem Zweck kann man natürlich eine for-Schleife nutzen. Im folgenden addieren wir 2 zu den Werten dieser Liste:
# prog4web
lst = [2,3, 7.9, 3.3, 6.9, 0.11, 10.3, 12.9]
res = []
for val in lst:
res.append(val + 2)
print(res)
Obwohl diese Lösung funktioniert, ist sie nicht elegant und pythonisch. Zu diesem Zweck nutzt man besser eine Listenabstraktion (englisch: list comprehension) statt der umständlichen Lösung mit for-Schleife. Wir empfehlen unser Kapitel über Listenabstraktion unseres Python-Tutorials, falls jemand mit der Thematik nicht oder nicht mehr vertraut sein sollte.
# prog4web
res = [ val + 2 for val in lst]
print(res)
Obwohl wir bereits einen Zeitvergleich zwischen NumPy und reinem Python durchgeführt hatten, wollen wir dennoch auch diese beiden Ansätze vergleichen:
# prog4web
v = np.random.randint(0, 100, 1000)
%timeit v + 1
# prog4web
lst = list(v)
%timeit [ val + 2 for val in lst]
Arithmetische Operationen auf zwei Arrays
Falls wir ein weiteres Array statt einem Skalar benutzen, werden die Elemente von beiden Arrays komponentenweise miteinander verknüpft.
Das Array verzehr_in_gramm enthält den Verzehr einer fiktiven Person, die genauestens über ihren Esskonsum buchführt. Die Kalorienaufnahme pro Lebensmittel können wir dann mittels einer komponentenweisen Multiplikation mit dem Array bestimmen:
# prog4book
import numpy as np
kalorientabelle = np.array([30, 52, 88, 36, 86,
160, 375, 115, 43, 71])
verzehr_in_gramm = np.array([240, 95, 135, 120, 200,
160, 290, 450, 500, 0])
kalorien_aufgenommen = kalorientabelle * verzehr_in_gramm / 100
print(kalorien_aufgenommen)
print(kalorien_aufgenommen.sum())
import numpy as np
A = np.array([[11, 12, 13], [21, 22, 23], [31, 32, 33]])
B = np.array([[5, 4, 2], [1, 0, 2], [3, 8, 2]])
print("Addition zweier Arrays: ")
print(A + B)
print("\nMultiplikation zweier Arrays: ")
print(A * B)
A * B im vorigen Beispiel sollte keinesfalls mit der Matrizenmultiplikation verwechselt werden. Wie bereits gesagt werden in unserem Beispiel die Arrays nur komponentenweise multipliziert!
Definition der dot-Funktion
In englischen Texten wird häufig bei dieser NumPy-Funktionalität vom "dot product" gesprochen. Mathematisch versteht man unter dem "dot product" das Skalarprodukt oder "innere Produkt" von zwei Vektoren. Seltener wird auch die Bezeichnung "Punktprodukt", also die wörtliche Übersetzung von "dot product", für das Skalarprodukt verwendet. Da das Skalar- oder Punktprodukt in der Mathematik üblicherweise nur für den eindimensionalen Fall bei Vektoren definiert ist und die dot-Funktion von NumPy aber auf beliebige Funktionen angewendet werden kann, sprechen wir von dot-Funktion, um Verwechslungen zur Mathematik vorzubeugen.
Die Syntax der dot-Funktion sieht wie folgt aus:
dot(a, b, out=None)
Die Funktion dot liefert das dot-Produkt von
a und b zurück.
Falls sowohl a als auch b Skalare sind oder beide eindimensionale Arrays, wird ein Skalar zurückgegeben, ansonsten ein Array.
Für eindimensionale Arrays entspricht es dem Skalarprodukt, auch inneres Produkt genannt, von Vektoren, jedoch ohne komplexe Konjugation.
Für zweidimensionale Arrays entspricht das dot-Produkt der Matrizenmultiplikation.
Für N Dimensionen wird das Summenprodukt über die letzte Achse von a und die vorletzte Achse von b gebildet.
Diesen Fall werden wir im Folgenden noch an Beispielen verdeutlichen.
Die Funktion erhebt einen ValueError, falls die Shape der letzten Dimension von a nicht die gleiche Größe wie die Shape der zweitletzten Dimension von b hat, d.h. es muss gelten a.shape[-1] == b.shape[-2].
Beispiele zur dot-Funktion
Wir beginnen mit den Fällen, in denen beide Argumente Skalare oder eindimensionale Arrays sind:
print(np.dot(3, 4))
x = np.array([3])
y = np.array([4])
print(x.ndim)
print(np.dot(x, y))
x = np.array([3, -2])
y = np.array([-4, 1])
print(np.dot(x, y))
Im zweidimensionalen Fall realisiert die dot-Funktion die Matrizenmultiplikation. Betrachten wir dazu folgendes Beispiel
import numpy as np
A = np.array([[11, 12, 13, 14],
[21, 22, 23, 24],
[31, 32, 33, 34]])
B = np.array([[5, 4, 2],
[1, 0, 2],
[3, 8, 2],
[24, 12, 57]])
print(np.dot(A, B))
Seit Python 3.5 gibt es für das dot-Produkt auch einen Infix-Operator, und zwar @:
print(A @ B)
Damit die Matrizenmultiplikation (also dot) für zwei Matrizen A und B im zweidimensionalen Fall funktionieren kann, muss gelten:
A.shape[-1] == B.shape[-2]
# es muss gelten:
print(A.shape[-1] == B.shape[-2])
Aus dem vorigen Beispiel können wir lernen, dass die Anzahl der Spalten des ersten zweidimensionalen Arrays gleich der Anzahl der Zeilen des zweiten zweidimensionalen Arrays sein muss.
import numpy as np
X = np.array( [[[3, 1, 2],
[4, 2, 2],
[2, 4, 1]],
[[3, 2, 2],
[4, 4, 3],
[4, 1, 1]],
[[2, 2, 1],
[3, 1, 3],
[3, 2, 3]]])
Y = np.array( [[[2, 3, 1],
[2, 2, 4],
[3, 4, 4]],
[[1, 4, 1],
[4, 1, 2],
[4, 1, 2]],
[[1, 2, 3],
[4, 1, 1],
[3, 1, 4]]])
R = np.dot(X, Y)
print("Die Größen:")
print(X.shape)
print(Y.shape)
print(R.shape)
print("\nDas Ergebnis der Matrizenmultiplikation:")
print(R)
Nun betrachten wir das Produkt von zwei nicht-symmetrischen dreidimensionalen Arrays:
import numpy as np
X = np.array( [ [[11, 12, 13], [14, 15, 16], [17, 18, 19]],
[[21, 22, 23], [24, 25, 26], [27, 28, 29]],
[[31, 32, 33], [34, 34, 35], [36, 37, 39]]])
Y = np.array( [[[0, 0, 0],
[0, 1, 0],
[0, 0, 1]]])
R = np.dot(X, Y)
print("Die Gestalten und die Dimensionen:")
print("X.shape: ", X.shape, " X.ndim: ", X.ndim)
print("Y.shape: ", Y.shape, " Y.ndim: ", Y.ndim)
print("R.shape: ", R.shape, "R.ndim: ", R.ndim)
print("\nDas Ergebnis-Array R:\n", R)
Die Funktion squeeze erlaubt uns, Dimensionen zu schrumpfen, indem eindimensionale Einträge aus der shape eines Arrays entfernt werden. Wir zeigen dies an einem einfachen Beispiel:
x = np.array([3, 5, 7]).reshape(1, 3, 1)
print(x)
print("x.squeeze()")
print(x.squeeze())
print("x.squeeze(axis=0)")
print(x.squeeze(axis=0))
print("x.squeeze(axis=2)")
print(x.squeeze(axis=2))
Nun wenden wir squeeze auf das Array R an, um die Shape von (3, 3, 1, 3) auf (3, 3, 3) zu schrumpfen:
print(R.shape)
R = np.squeeze(R, axis=2)
print(R.shape, R)
Um zu zeigen, wie das dot-Produkt im dreidimensionalen Fall funktioniert, werden wir jedoch nun zwei nicht-symmetrische dreidimensionale Arrays im folgenden Beispiel benutzen:
import numpy as np
X = np.array(
[[[3, 1, 2],
[4, 2, 2]],
[[-1, 0, 1],
[1, -1, -2]],
[[3, 2, 2],
[4, 4, 3]],
[[2, 2, 1],
[3, 1, 3]]])
Y = np.array(
[[[2, 3, 1, 2, 1],
[2, 2, 2, 0, 0],
[3, 4, 0, 1, -1]],
[[1, 4, 3, 2, 2],
[4, 1, 1, 4, -3],
[4, 1, 0, 3, 0]]])
R = np.dot(X, Y)
print("X.shape: ", X.shape, " X.ndim: ", X.ndim)
print("Y.shape: ", Y.shape, " Y.ndim: ", Y.ndim)
print("R.shape: ", R.shape, "R.ndim: ", R.ndim)
print("\nDas Ergebnis-Array R:\n")
print(R)
Schauen wir uns nun die folgenden Summen-Produkte an:
i = 0
for j in range(X.shape[1]):
for k in range(Y.shape[0]):
for m in range(Y.shape[2]):
fmt = " sum(X[{}, {}, :] * Y[{}, :, {}] : {}"
arguments = (i, j, k, m, sum(X[i, j, :] * Y[k, :, m]))
print(fmt.format(*arguments))
Hoffentlich ist Ihnen aufgefallen, dass die Werte, die wir erzeugt haben, den Elementen von R[0] entsprechen:
print(R[0])
Dies bedeutet, dass wir das Array R auch über die Summen-Produkte hätten erzeugen können. Um dies zu "beweisen", werden wir im folgenden Beispiel ein Array R2 unter Benutzung der Summen-Produkte erzeugen. Anschließend prüfen wir, ob R2 gleich R ist.
def sum_prod(X, Y):
""" sum product for 3-dimensional arrays """
res_shape = X.shape[:-1] + Y.shape[:-2] + (Y.shape[-1],)
R = np.zeros(res_shape, dtype=type(X))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
for k in range(Y.shape[0]):
for m in range(Y.shape[2]):
R[i, j, k, m] = sum(X[i, j, :] * Y[k, :, m])
return R
print( np.array_equal(np.dot(X, Y), sum_prod(X, Y)) )
Es gilt also, was wir eingangs behauptet haben:
dot(X, Y)[i,j,k,m] = sum(X[i,j,:] * Y[k,:,m])
Wir kennen bereits Vergleichsoperatoren in Python, die wir auf Integer, Floats oder Strings angewendet haben. Sie liefern True oder False zurück. Vergleichen wir zwei Arrays miteinander, erhalten wir keinen "einfachen" Booleschen Wert zurück. Die Vergleiche werden elementweise durchgeführt. Dies bewirkt, dass wir ein Boolesches Array als Rückgabewert erhalten:
import numpy as np
A = np.array([ [11, 12, 13], [21, 22, 23], [31, 32, 33] ])
B = np.array([ [11, 102, 13], [201, 22, 203], [31, 32, 303] ])
A == B
Man kann aber auch Arrays vollständig auf Gleichheit überprüfen. Dazu benutzen wir die Funktion array_equal, die True zurückliefert, falls zwei Arrays die gleiche Shape haben und alle Elemente gleich sind. Ansonsten wird False zurückgeliefert.
print(np.array_equal(A, B))
print(np.array_equal(A, A))
a = np.array([ [True, True], [False, False]])
b = np.array([ [True, False], [True, False]])
print(np.logical_or(a, b))
print(np.logical_and(a, b))
Broadcasting
Bisher gingen wir davon aus, dass Arrays die gleiche Shape haben müssen, damit wir numerische Operatoren auf diese anwenden können. Unter dem Namen "Broadcasting" stellt NumPy einen mächtigen Mechanismus zur Verfügung, der es erlaubt, arithmetische Operatoren auch auf Arrays mit unterschiedlicher Shape anzuwenden. Um die entsprechende Operation durchzuführen, wird nun das "kleinere" Array entweder in eine "passende Form" transformiert oder mehrmals auf das "größere" angewendet. In anderen Worten: Unter bestimmten Bedingungen erfolgt ein "Broadcast" des kleineren Arrays, bis es die gleiche Shape wie das größere hat.
Mit Hilfe des Broadcasting können wir Schleifen in unseren Python-Programmen vermeiden. Die Schleifenbildung erfolgt dann implizit in der NumPy-Implementierung, d.h. in C. Dadurch vermeiden wir außerdem unnötige Kopien von unseren Daten.
Prinzipiell gibt es drei verschiedene Formen von Broadcasting:
- in horizontaler Richtung
- in vertikaler Richtung
- in horizontaler und vertikaler Richtung
Broadcasting bei zwei Arrays in NumPy erfolgt nach folgenden Regeln:
Regel 1
Falls die beiden Arrays in ihrer Anzahl von Dimensionen sich unterscheiden, wird die
Shape des Arrays, das weniger Dimensionen hat, mit Einsen von der linken Seite aus
aufgefüllt.
Regel 2
Falls die Shapes von zwei Arrays an einer Shape-Position nicht übereinstimmen, wird die Shape desjenigen Arrays angepasst, die eine 1 enthält. Der Wert wird dann auf den Wert des anderen Arrays erhöht.
Regel 3
Falls in irgendeiner Dimension die Größen unterschiedlich sind und keine von beiden gleich 1 ist, wird ein Fehler erhoben.
Im Folgenden werden wir klarer sehen, was die Anwendung dieser Regeln bewirken.
Einen besonders einfachen Fall von Broadcasting haben wir schon kennengelernt. Der einfachste Fall ist die Skalarenmultiplikation:
import numpy as np
v = np.array([3, 5, 1])
x = 4
print(v * x)
Statt einem Skalar für x hätte man auch den Vektor np.array([4, 4, 4]) nehmen können und hätte das gleiche Ergebnis erhalten:
import numpy as np
v = np.array([3, 5, 1])
x = np.array([4, 4, 4])
print(v * x)
import numpy as np
A = np.array([[11, 12, 13],
[21, 22, 23],
[31, 32, 33] ])
B = np.array([1, 2, 3])
print(A.shape)
print(B.shape)
print("Multiplikation mit Broadcasting: ")
print(A * B)
print("... und nun die Addition mit Broadcasting: ")
print(A + B)
Das folgende Diagramm illustriert die Arbeitsweise von Broadcasting:
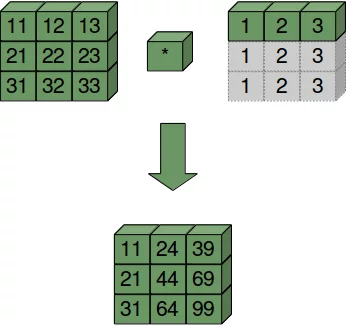
B wird benutzt, als wäre es wie folgt aufgebaut:
B = np.array([1, 2, 3])
print("Die Shape von B: ", B.shape)
# Anwendung der Regel 1:
B = B[np.newaxis, :]
print("Shape nach Anwendung der ersten Regel: ", B.shape)
B = np.tile(B, (3, 1))
print("Shape nach Anwendung der zweiten Regel: ", B.shape)
print()
print(B)
"Zeilenweise" bedeutet also, dass wir ein eindimensionales Array als die zu broadcastende Zeile betrachten.
Broadcasting funktioniert auch bei höheren Dimensionen, solange sich die beiden ersten Regeln erfolgreich anwenden lassen. Wir demonstrieren dies im folgenden Beispiel:
X = np.array(
[[[2, 3, 1, 2, 1],
[2, 2, 2, 0, 0],
[3, 4, 0, 1, -1]],
[[1, 4, 3, 2, 2],
[4, 1, 1, 4, -3],
[4, 1, 0, 3, 0]]])
print(Y.shape)
X = np.array([1, 2, 3, 4, 5])
print(X + Y)
Auch in diesem Falle wollen wir uns anschauen, was man machen müsste, um das Broadcasting nach den Regeln zu simulieren:
print(Y.shape)
X = X[np.newaxis, np.newaxis, :]
print("Shape nach Anwendung der ersten Regel: ", X.shape)
X = np.tile(X, (2, 3, 1))
print("Shape nach Anwendung der zweiten Regel: ", X.shape)
print()
print(X + Y)
In diesem Fall haben wir wieder ein eindimensionales Array, betrachten es nun aber als Spaltenvektor des Broadcast-Arrays.
Für dieses Beispiel müssen wir wissen, wie man einen Zeilenvektor in einen Spaltenvektor wandelt. Hierzu gibt es zwei Möglichkeiten. Mittels reshape:
B = np.array([1, 2, 3])
print(B.reshape((B.shape[0], 1)))
Alternativ können wir auch newaxis verwenden:
B = np.array([1, 2, 3])
print(B[:, np.newaxis])
Nun können wir die Multiplikation mittels Broadcasting durchführen:
import numpy as np
A = np.array([[11, 12, 13],
[21, 22, 23],
[31, 32, 33] ])
A * B[:, np.newaxis]
B wird benutzt als wäre es wie folgt aufgebaut:
B = np.array([1, 2, 3])
B = B.reshape((B.shape[0], 1))
print("Shape nach Anwendung der ersten Regel: ", B.shape)
B = np.tile(B, (1, 3))
print("Shape nach Anwendung der zweiten Regel: ", B.shape)
print()
print(B)
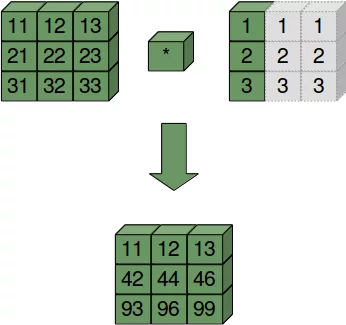
Broadcasting von zwei eindimensionalen Arrays
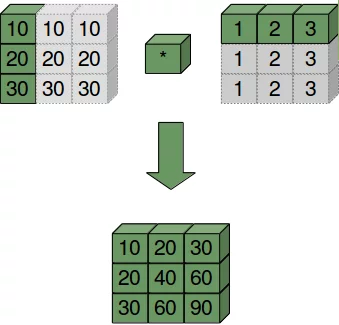
Nun betrachten wir den Fall, dass wir zwei eindimensionale Arrays verknüpfen möchten. Den ersten wollen wir als Spaltenvektor betrachten und den zweiten als Zeilenvektor. Im Prinzip kombinieren wir nun die Verfahren der beiden vorigen Fälle, also spaltenweises und zeilenweises Broadcasting:
A = np.array([10, 20, 30])
B = np.array([1, 2, 3])
# wir richten A auf:
A = A.reshape(A.shape[0], 1)
print(A)
# nun können wir das Broadcasting durchführen:
print(A * B)
In der Mathematik, der Informatik und insbesondere in der Graph-Theorie, versteht man unter der Distanzmatrix ein zweidimensionales Array, das die "Entfernungen" zwischen den Elementen einer Menge paarweise beinhaltet. Die Größe dieses zweidimensionalen Arrays ist n x n, falls die Menge aus n Elementen besteht.
Ein praktisches Beispiel einer Distanzmatrix ist eine Matrix mit den Entfernungen zwischen geografischen Lokationen, in unserem Beispiel europäische Städte:
cities = ["Barcelona", "Berlin", "Brüssel", "Bukarest",
"Budapest", "Kopenhagen", "Dublin", "Hamburg",
"Istanbul", "Kiew", "London", "Madrid",
"Mailand", "Moskau", "München", "Paris", "Prag",
"Rome", "Sankt Petersburg", "Stockholm", "Wien",
"Warschau"]
dist2barcelona = [0, 1498, 1063, 1968,
1498, 1758, 1469, 1472, 2230,
2391, 1138, 505, 725, 3007, 1055,
833, 1354, 857, 2813,
2277, 1347, 1862]
dists = np.array(dist2barcelona[:12])
print(dists)
print(np.abs(dists - dists[:, np.newaxis]))
Ufuncs
Bisher haben wir diverse Operatoren wie Addition, Subtraktion, Multiplikation und so weiter für Arrays kennengelernt. Allen sind bestimmte Features gemeinsam, wie Broadcasting und erzwungene Typumwandlung (englisch: type coercion). Allen Operationen ist auch die elementweise Anwendung gemeinsam.
Zu den bereits kennengelernten Infix-Operatoren wie $+$, $-$, $*$ und so weiter gibt es auch Funktionen wie add, subtract, multiply, divide, remainder, power und weitere. Aber es gibt auch Funktionen, für die es keine Infix-Variante gibt, da es sich um Funktionen handelt, die nur ein Argument erwarten, also unäre Operatoren: arccos, arccosh, arcsin, arcsinh, arctan, arctanh, cos, cosh, tan, tanh,
log10, sin, sinh, sqrt, absolute, fabs, floor, ceil, fmod, exp, log, conjugate, maximum, minimum.
Auch für die Infix-Vergleichsoperatoren <, <=, ==, >, >=, != und so weiter gibt es entsprechende funktionale Varianten: greater, greater_equal, equal, less, less_equal, not_equal, logical_or, logical_xor, logical_not, logical_and, bitwise_or, bitwise_xor, bitwise_not, bitwise_and, rshift, lshift
Diese Funktionen bezeichnet man als Ufuncs, auch als universelle Funktionen bekannt.
Anwendung von Ufuncs
Die funktionalen und Infix-Varianten sind äquivalent.
import numpy as np
from numpy import add
x = np.array([3, 5, -1, 0])
y = np.array([1, -2, 0, 3])
print(x + y)
# äquivalente Möglicheit
print(add(x, y))
print("Typ der 'add'-Funktion:", type(add))
Die Ufuncs lassen sich auf beliebige Python-Sequenzen anwenden, sofern sie aus numerischen Datentypen bestehen und bezüglich ihrer Längen und Shapes übereinstimmen:
import numpy as np
x = [2, 5, 6.7]
y = [4, 6, 7.8]
print(np.add(x, y))
print(np.add(tuple(x), y))
print(np.add(x, range(3)))
Die unären Ufunc-Funktionen können sowohl auf NumPy-Arrays als auch auf andere Python-Sequenzen angewendet werden. Der Rückgabewert ist aber in allen Fällen ein numpy.ndarray-Wert:
import numpy as np
x = [2, 5, 6.7]
v = np.array(x)
res = np.sin(x)
print(res, type(res))
res = np.sin(v)
print(res, type(res))
res = np.sin(range(1, 100, 7))
print(res, type(res))
Sie können auch auf Instanzen der int- und float-Klassen aufgerufen werden. Rückgabewerte sind in diesen Fällen numpy.int64- bzw. numpy.float64-Typen:
res = np.sin(2)
print(res, type(res))
res = np.ceil(2.3)
print(res, type(res))
import numpy as np
x = np.array([25.6, 29.3, 30.9])
x = x * 1.8
# oder äquivalent dazu in Ufunc-Schreibweise
x = np.array([25.6, 29.3, 30.9])
x = np.multiply(x, 1.8)
print(x)
In den obigen Fällen wurde zuerst ein neues ndarray-Array mit dem Ergebnis erzeugt und dann wurde dieses Array der Variablen x zugewiesen. Das alte Array wird danach nicht mehr benötigt und muss gelöscht werden.
Indem wir die Variable x als Rückgabeparameter spezifizieren, wird die Operation in-place durchgeführt, also effizienter:
import numpy as np
x = np.array([25.6, 29.3, 30.9])
np.multiply(x, 1.8, x)
print(x)
Die in-place-Variante mit Rückgabeparameter ist im Allgemeinen deutlich schneller, aber nicht immer, wie wir im Folgenden sehen können:
import timeit
setup = 'import numpy as np; A = np.random.random((100, 100))'
for i in range(5):
time1 = timeit.timeit("A = np.multiply(A, 1.0234)",
setup=setup,
number=10)
time2 = timeit.timeit("np.multiply(A, 1.0234, A)",
setup=setup,
number=10)
print(time1, time2, time1/time2)
accumulate
Auf die Ufunc-Funtionen kann die accumulate-Methode angewendet werden.
Die accumulate-Funktion bewirkt die Anwendung des Operators auf alle Elemente des Arrays und der darauffolgenden Akkumulation der Ergebnisse.
Wendet man accumulate auf die add-Funktion an, erhält man eine zu np.cumsum äquivalente Funktionalität, wie wir im folgenden Beispiel demonstrieren.
import numpy as np
x = np.arange(1, 6)
print(x)
print(np.add.accumulate(x))
print(np.cumsum(x))
Den mehrdimensionalen Fall und die Benutzung des optionalen Parameters axis verdeutlichen wir mit folgendem selbsterklärenden Beispiel:
import numpy as np
x = np.arange(24).reshape((6, 4))
print(x)
print("Akkumulation über Zeilen, d.h. axis = 0:")
print(np.add.accumulate(x))
print("Akkumulation über Zeilen, d.h. axis = 0:")
print(np.add.accumulate(x, axis=0))
print("Akkumulation über Spalten, d.h. axis = 1:")
print(np.add.accumulate(x, axis=1))
print("Akkumulation über Zeilen und Spalten:")
print(np.add.accumulate(np.add.accumulate(x, axis=0), axis=1))
reduce
Die Arbeitsweise von reduce im eindimensionalen Fall, kann wie folgt beschreiben werden:
Nehmen wir an, op ist eine Funktion wie numpy.add oder numpy.multiply.
Wendet man op.reduce auf ein Objekt x an, welches eine numerische Python-Sequenz oder ein eindimensionales Array sein kann, so liefert sie einen einzelnen Wert zurück. Die Berechnung geschieht wie folgt:
Falls x leer ist, wird 0.0 zurückgeliefert. Besitzt x nur ein Element, wird dieses als Ergebnis von op.reduce(x) zurückgeliefert. Bei mehr als einem Element in x wird op zuerst auf die ersten beiden Elemente von x angewendet. Gibt es noch weitere Elemente, wird op auf dieses Ergebnis und auf das folgende Element von x angewendet. Dies wird solange fortgesetzt, bis es keine weiteren Elemente mehr gibt, und das letzte Ergebnis wird dann als Gesamtergebnis zurückgeliefert:
import numpy as np
x = np.arange(1, 5)
print(np.add.reduce(x)) # äquivalent zu ```sum```
print(np.multiply.reduce(x)) # äquivalent zu ```factorial```
Im mehrdimensionalen Fall bewirkt die Anwendung von reduce die Reduktion um eine Dimension. Eine Reduktion über alle Dimensionen erhält man, indem man axis auf None setzt:
import numpy as np
x = np.arange(12).reshape((3, 4))
print(x)
print("Reduce über Zeilen, d.h. axis = 0:")
print(np.add.reduce(x))
print("Reduce über Spalten, d.h. axis = 1:")
print(np.add.reduce(x, axis=1))
print("Reduce über Zeilen und Spalten:")
print(np.add.reduce(np.add.reduce(x)))
print("Letzteres geht einfacher mit axis = None:")
print(np.add.reduce(x, axis=None))
import numpy as np
np.multiply.outer([1, 2, 3, 4], [11, 22, 33])
import numpy as np
a = np.array([3, 5, 12, 5])
b = np.array([3, 11])
np.add.at(a, [0, 2], b)
print(a)
# äquivalent mit
a = np.array([3, 5, 12, 5])
a[[0, 2]] += b
print(a)
# nun mit mehrfachen Indizes:
a = np.array([3, 5, 12, 5])
np.add.at(a, [0, 0], b)
print(a)
a[[0, 0]] += b
print(a)
# prog4book
B = np.array([1, 2, 3])
print(B.shape)
B = B[np.newaxis, :]
print(B.shape)
B = np.concatenate((B, B, B)).transpose()
print(B.shape)
B = B[:, np.newaxis]
print(B.shape)
print(B)
# prog4book
A = np.random.randint(-10, 10, (3, 4))
print(A)
print("Zeilenminima: ")
print(np.min(A, axis=1))
print("Spaltenminima: ")
print(np.min(A, axis=0))
print("Absolutes Minimum: ")
print(np.min(A))
# prog4book
# prog4book
A = np.random.randint(-10, 10, (3, 4))
print(A)
print("Zeilenminima: ")
print(np.min(A, axis=1))
print("Spaltenminima: ")
print(np.min(A, axis=0))
print("Absolutes Minimum: ")
print(np.min(A))