

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

Nächstes Kapitel: Einnahme-Überschuss-Rechnung mit Python und Pandas
Haushaltsbuch¶

In diesem Kapitel unseres Pandas-Tutorials werden wir uns mit einfachen Ausgaben- und Einkommenstabellen für den privaten Gebrauch befassen. Einige sagen, wenn man Geld erfolgreich verwalten möchte, muss man die Einnahmen und Ausgaben genau verfolgen. Die Überwachung des Geldflusses ist wichtig, um die eigene finanzielle Situation besser zu verstehen. Man muss genau wissen, wie viel ein- und ausgeht. Dazu bedient man sich üblicherweise eines Haushaltsbuches, indem alle Ein- und Ausgaben protokolliert sind. Dieser Artikel will niemanden von der Notwendigkeit überzeugen, dies zu tun. Das Hauptaugenmerk liegt vielmehr auf den Möglichkeiten, die Python und Pandas bieten, um die erforderlichen Tools zu programmieren. Wir zeigen Verfahren, um eine Haushaltsbuch auszuwerten.
Wir beginnen mit einem kleinen Beispiel, das für private Zwecke geeignet ist. Im folgenden Kapitel unseres Pandas-Tutorials wird ein ausführlicheres Beispiel behandelt, welches für kleine Unternehmen geeignet ist.
Private Haushaltsplanung mit Python und Pandas¶
Nehmen wir an, Sie haben bereits eine CSV-Datei, die Ihre Ausgaben und Einnahmen über einen bestimmten Zeitraum enthält. Dieses Tagebuch könnte folgendermaßen aussehen:
Datum;Beschreibung;Kategorie;Ausgaben;Einnahmen
2020-06-02;Gehalt Frank;Einkommen;0;4896.44
2020-06-03;Supermarkt;Essen und Getränke;132.40;0
2020-06-04;Gehalt Laura;Einkommen;0;4910.14
2929-06-04;Stadtwerke (Strom);Betriebskosten;87.34;0
2020-06-09;Stadtwerke (Wasser und Abwasser);Betriebskosten;60.56;0
2020-06-10;Fitnessstudio, Jane;Gesundheit und Sport;19.00;0
2020-06-11;Bank;Kredittilgung;1287.43;0
2020-06-12;LeGourmet Restaurant;Restaurants und Hotels;145.00;0
2020-06-13;Supermarkt;Essen und Getränke;197.42;0
2020-06-13;Pizzeria da Pulcinella;Restaurants und Hotels;60.00;0
2020-06-26;Supermarkt;Essen und Getränke;155.42;0
2020-06-27;Theatertickets;education and culture;125;0
2020-07-02;Gehalt Frank;Einkommen;0;4896.44
2020-07-03;Supermarkt;Essen und Getränke;147.90;0
2020-07-05;Gehalt Laura;Einkommen;0;4910.14
2020-07-08;Golf Club, jährliche Zahlung;Gesundheit und Sport;612.18;0
2020-07-09;Hausversicherung;Versicherungen;167.89;0
2020-07-10;Fitnessstudio, Jane;Gesundheit und Sport;19.00;0
2020-07-10;Supermarkt;Essen und Getränke;144.12;0
2020-07-11;Banküberweisung;Kredittilgung;1287.43;0
2020-07-18;Supermarkt;Essen und Getränke;211.24;0
2020-07-13;Pizzeria da Pulcinella;Restaurants und Hotels;33.00;0
2020-07-23;Kinobesuch;Kultur und Weiterbildung;19;0
2020-07-25;Supermarkt;Essen und Getränke;186.11;0Die oben genannte CSV-Datei wird unter dem Namen ein_und_ausgaben.csv im Ordner data gespeichert. Es ist einfach, sie mit Pandas einzulesen, wie wir in unserem Kapitel Dateien lesen und schreiben mit Pandas sehen können:
import pandas as pd
import os
print(os.getcwd())
exp_inc = pd.read_csv("data1/ein_und_ausgaben.csv", sep=";")
exp_inc
Durch Lesen der CSV-Datei haben wir ein DataFrame-Objekt erstellt. Was können wir damit machen oder mit anderen Worten: Welche Informationen interessieren Frank und Laura? Natürlich interessieren sie sich für den Kontostand. Sie wollen wissen, wie hoch das Gesamteinkommen war, und sie wollen die Summe aller Ausgaben sehen.
Die Salden ihrer Ausgaben und Einnahmen können leicht berechnet werden, indem die Funktion sum auf das DataFrameexp_inc[['Out', 'In']]-Objekt angewendet:
exp_inc[['Ausgaben', 'Einnahmen']].sum()
Welche weiteren Informationen möchten sie aus den Daten gewinnen? Sie könnten daran interessiert sein, die Ausgaben nach den verschiedenen Kategorien zusammengefasst zu sehen. Dies lässt sich mittels groupby und sum bewerkstelligen:
category_sums = exp_inc.groupby("Kategorie").sum()
category_sums
category_sums.index
import matplotlib.pyplot as plt
ax = category_sums.plot.bar(y="Ausgaben")
plt.xticks(rotation=45)
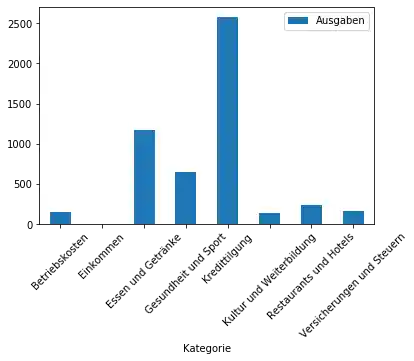
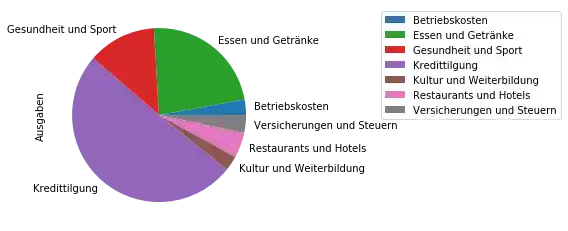
Wir können dies auch als Tortendiagramm darstellen:
ax = category_sums.plot.pie(y="Ausgaben")
ax.legend(loc="upper left", bbox_to_anchor=(1.5, 1))
Alternativ können wir dasselbe Kreisdiagramm mit dem folgenden Code erstellen:
ax = category_sums["Ausgaben"].plot.pie()
ax.legend(loc="upper left", bbox_to_anchor=(1.5, 1))
If you imagine that you will have to type in all the time category names like "household goods and service" or "rent and mortgage interest", you will agree that it is very likely to have typos in your journal of expenses and income.
So it will be a good idea to use numbers (account numbers) for your categories. The following categories are available in our example.
The following categories are provided:
Wenn man sich vorstellt, dass man die ganze Zeit Kategorienamen wie "Essen und Getränke" oder "Restaurants und Hotels" eingeben muss, kann man sich leicht vorstelltn, dass sich leicht Tippfehler im Ausgaben- und Einnahmenjournal einschleichen können.
Es ist daher eine gute Idee, Nummern (Kontonummern) für die Kategorien zu verwenden. Die folgenden Kategorien sind in unserem Beispiel verfügbar:
| Kategorie | Kontonummer |
|---|---|
| Kredittilgung | 200 |
| Versicherungen und Steuern | 201 |
| Essen und Getränke | 202 |
| Kultur und Weiterbildung | 203 |
| Transport | 204 |
| Gesundheit und Sport | 205 |
| Haushalt und Dienstleistungen | 206 |
| Kleidung | 207 |
| Kommunikationskosten | 208 |
| Restaurants und Hotels | 209 |
| Betriebskosten (Heizung, Strom, Wasser, Müll) | 210 |
| andere Ausgaben | 211 |
| Einkommen | 400 |
Wir können dies als Python dictionary implementieren, das Kategorien in Kontonummern abbildet:
category2account = {"Kredittilgung": "200",
"Versicherungen und Steuern": "201",
"Essen und Getränke": "202",
"Kultur und Weiterbildung": "203",
"Transport": "204",
"Gesundheit und Sport": "205",
"Haushalt und Dienstleistungen": "206",
"Kleidung": "207",
"Kommunikationskosten": "208",
"Restaurants und Hotels": "209",
"Betriebskosten": "210",
"andere Ausgaben": "211",
"Einkommen": "400"}
Der nächste Schritt besteht darin, unsere "unhandlichen" Kategorienamen durch die Kontonummern zu ersetzen. Die Ersetzungsmethode replace von DataFrame ist für diesen Zweck ideal. Wir können alle Vorkommen der Kategorienamen in unserem DataFrame durch die entsprechenden Kontonamen ersetzen:
exp_inc.replace(category2account, inplace=True)
exp_inc.rename(columns={"Category": "Accounts"}, inplace=True)
exp_inc
Wir werden dieses DataFrame-Objekt jetzt in einer Excel-Datei speichern. Diese Excel-Datei enthält zwei Blätter: eines mit dem Journal "Ausgaben und Einnahmen" und das andere mit der Zuordnung von Kontonummern zu Kategorienamen. Zu diesem Zweck verwandeln wir das category2account-Dictionary in ein Series-Objekt. Als Index dienen die Kontonummern:
We will save this DataFrame object now in an excel file. This excel file will have two sheets: One with the "expenses and income" journal and the other one with the mapping of account numbers to category names.
We will turn the category2account dictionary into a Series object for this purpose. The index will be the account numbers:
account_numbers = pd.Series(list(category2account.keys()), index=category2account.values())
account_numbers.name = "Beschreibung"
account_numbers.rename("Kontonummern")
exp_inc.insert(1, "Kontonummern", account_numbers)
with pd.ExcelWriter('data1/expenses_and_income_2020.xlsx') as writer:
account_numbers.to_excel(writer, "account numbers")
exp_inc.to_excel(writer, "journal")
writer.save()
Nächstes Kapitel: Einnahme-Überschuss-Rechnung mit Python und Pandas