

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

Nächstes Kapitel: Nächste Nachbarn-Klassifikation
Aufteilungen der Daten¶
Datensets in Lern- und Testsets trennen¶

Sie haben Ihre Daten bereit und möchten den Klassifikator trainieren? Aber seien Sie vorsichtig: Wenn Ihr Klassifikator fertig ist, benötigen Sie einige Testdaten, um Ihren Klassifikator zu bewerten. Wenn Sie Ihren Klassifikator mit den zum Lernen verwendeten Daten bewerten, sehen Sie möglicherweise überraschend gute Ergebnisse. Was wir tatsächlich testen möchten, ist die Leistung der Klassifizierung auf unbekannten Daten.
Zu diesem Zweck müssen wir unsere Daten in zwei Teile aufteilen:
- Einen Trainingssatz, mit dem der Lernalgorithmus das Modell anpasst oder lernt
- Ein Testset zur Bewertung der Generalisierungsleistung des Modells
Wenn man bedenkt, wie das maschinelle Lernen normalerweise funktioniert, ist die Idee einer Aufteilung zwischen Lern- und Testdaten sinnvoll. Real existierende Systeme trainieren auf existierenden Daten und wenn dann andere also neue Daten (von Kunden, Sensoren oder anderen Quellen) kommen, muss der trainierte Klassifikator diese neue Daten vorhersagen bzw. klassifizieren. Wir können dies während des Trainings mit einem Trainings- und Testdatenset simulieren - die Testdaten sind eine Simulation von "zukünftigen Daten", die während der Produktion in das System eingehen werden.
In diesem Kapitel unseres Tutorials über Maschinelles Lernen mit Python erfahren Sie, wie Sie die Aufspaltung mit einfachem Python tun können. Danach werden wir zeigen, dass es nicht notwendig ist, dies manuell zu tun, da die Funktion train_test_split aus dem Modul model_selection dies für uns tun kann.
Wenn der Datensatz nach Labels sortiert ist, müssen wir ihn vor dem Teilen mischen.
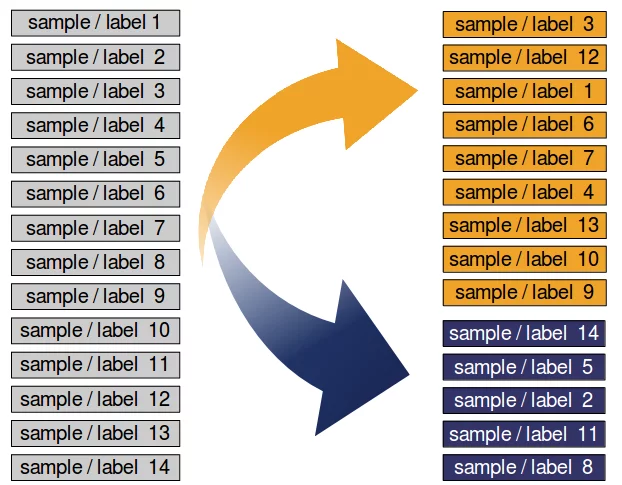
Wir haben den Datensatz in einen Lerndatensatz (a.k.a. Training) und einen Testdatensatz unterteilt. Die beste Vorgehensweise besteht darin, es in einen Lern-, Test- und Bewertungsdatensatz aufzuteilen.
Wir werden unser Modell (Klassifikator) Schritt für Schritt trainieren und jedes Mal, wenn das Ergebnis getestet werden muss. Wenn wir nur einen Testdatensatz haben. Die Testergebnisse könnten in das Modell einfließen. Daher werden wir einen Bewertungsdatensatz für die gesamte Lernphase verwenden.
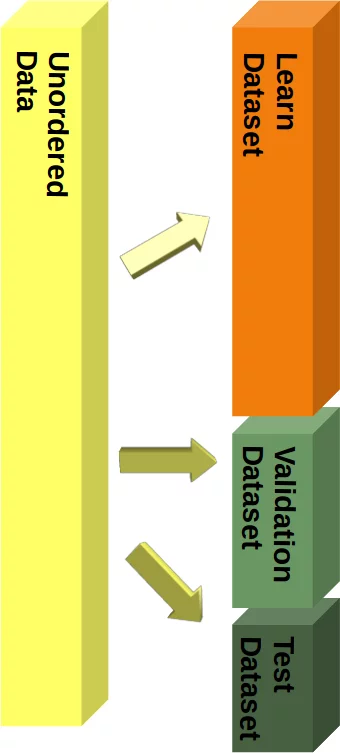
In unserem Tutorial werden wir jedoch nur Aufteilungen in Lern- und Testdatensätze verwenden.
Aufteilung des Iris-Datensatzes¶
Wir werden die zuvor besprochenen Themen anhand des Iris-Datensatzes demonstrieren.
Die 150 Datensätze des Iris-Datensatzes sind sortiert, d.h. die ersten 50 Daten entsprechen der ersten Blumeklasse (0 = Setosa), die nächsten 50 der zweiten Blumenklasse (1 = Versicolor) und die restlichen Daten entsprechen der letzten Klasse (2 = Virginica).
Würden wir nun unsere Daten im Verhältnis 2/3 (Lernset) und 1/3 (Testset) aufteilen, enthielte das Lernset alle Blumen der beiden ersten Klassen und das Testset alle Blumen der dritten Klasse. Der KLassifikator könnte also nur zwei Klassen lernen und die dritte Klasse wäre komplett unbekannt. Deshalb müssen wir die Daten dringend mischen.
Unter der Annahme, dass alle Stichproben unabhängig voneinander sind, möchten wir den Datensatz zufällig mischen, bevor wir den Datensatz wie oben dargestellt aufteilen.
Im Folgenden teilen wir die Daten manuell auf:
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
Wenn wir uns die Labels anschauen, sehen wir, dass die Daten, wie eben beschrieben, sortiert sind:
iris.target
Als erstes müssen wir die Daten neu anordnen, damit sie nicht mehr sortiert werden. Dazu benutzen wir die permutation-Funktion des random-Submoduls von Numpy:
indices = np.random.permutation(len(iris.data))
indices
n_training_samples = 12
learnset_data = iris.data[indices[:-n_training_samples]]
learnset_labels = iris.target[indices[:-n_training_samples]]
testset_data = iris.data[indices[-n_training_samples:]]
testset_labels = iris.target[indices[-n_training_samples:]]
print(learnset_data[:4], learnset_labels[:4])
print(testset_data[:4], testset_labels[:4])
Aufteilungen mit Sklearn¶
Obwohl es nicht schwierig war müssen wir die Aufteilung nicht, wie oben gezeigt, manuell durchführen. Da dies beim maschinellen Lernen häufig erforderlich ist, verfügt scikit-learn über eine vordefinierte Funktion zum Aufteilen von Daten in Trainings- und Testsätze.
Wir werden dies im Folgenden demonstrieren. Wir werden 80% der Daten als Trainings- und 20% als Testdaten verwenden. Ebensogut hätten wir 70% und 30% nehmen können, denn es gibt keine festen Regeln. Das Wichtigste ist, dass Sie Ihr System fair anhand von Daten bewerten, die es während des Trainings nicht gesehen hat! Außerdem müssen in beiden Datensätze genügend Daten enthalten sein.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
data, labels = iris.data, iris.target
res = train_test_split(data, labels,
train_size=0.8,
test_size=0.2,
random_state=42 # garantees same output for every run
)
train_data, test_data, train_labels, test_labels = res
n = 7
print(f"Die ersten {n}-Datensätze:")
print(test_data[:7])
print(f"Die zugehörigen ersten {n}-Labels:")
print(test_labels[:7])
Fahren wir fort, unsere Trainings- und Testdatensätze zu visualisieren. In unserem Diagramm werden grüne und blaue Punkte die Trainingsdaten darstellen, während hellgrüne und hellblaue Punkte die Testdaten symbolisieren.
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
# plotting learn data
colours = ('green', 'blue')
for n_class in range(2):
ax.scatter(train_data[train_labels==n_class][:, 0],
train_data[train_labels==n_class][:, 1],
c=colours[n_class], s=40, label=str(n_class))
# plotting test data
colours = ('lightgreen', 'lightblue')
for n_class in range(2):
ax.scatter(test_data[test_labels==n_class][:, 0],
test_data[test_labels==n_class][:, 1],
c=colours[n_class], s=40, label=str(n_class))
ax.plot();

Der folgende Code verbessert die Lesbarkeit und die Modularität, indem er eine separate Funktion für das Plotten der Daten erstellt. Außerdem wird dem Diagramm eine Legende zur besseren Interpretation der Klassen hinzugefügt:
import matplotlib.pyplot as plt
# Define function for scatter plot
def plot_data(data, labels, ax, colours, label):
for n_class, colour in enumerate(colours):
ax.scatter(data[labels == n_class][:, 0],
data[labels == n_class][:, 1],
c=colour, s=40, label=label.format(n_class))
# Create figure and axis objects
fig, ax = plt.subplots()
# Plot training data
train_colours = ['green', 'blue']
plot_data(train_data, train_labels, ax, train_colours, label="Training Class {}")
# Plot testing data
test_colours = ['lightgreen', 'lightblue']
plot_data(test_data, test_labels, ax, test_colours, label="Testing Class {}")
# Add legend
ax.legend()
# Show plot
plt.show()

Geschichtete Zufallsprobe¶
Insbesondere bei relativ kleinen Datenmengen ist es besser, die Aufteilung zu schichten. Schichtung bedeutet, dass wir den ursprünglichen Klassenanteil des Datensatzes in den Test- und Trainingssätzen beibehalten. Wir berechnen die Klassenanteile der vorherigen Aufteilung in Prozent unter Verwendung des folgenden Codes. Um die Anzahl der Vorkommen jeder Klasse zu berechnen, verwenden wir die Numpy-Funktion 'bincount'. Es zählt die Anzahl der Vorkommen jedes Werts in dem als Argument übergebenen Array nicht negativer Integers.
import numpy as np
print('All:', np.bincount(labels) / float(len(labels)) * 100.0)
print('Training:', np.bincount(train_labels) / float(len(train_labels)) * 100.0)
print('Test:', np.bincount(test_labels) / float(len(test_labels)) * 100.0)
Um die Aufteilung zu schichten, können wir das Label-Array als zusätzliches Argument an die Funktion train_test_split übergeben:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
data, labels = iris.data, iris.target
res = train_test_split(data, labels,
train_size=0.8,
test_size=0.2,
random_state=42,
stratify=labels)
train_data, test_data, train_labels, test_labels = res
print('All:', np.bincount(labels) / float(len(labels)) * 100.0)
print('Training:', np.bincount(train_labels) / float(len(train_labels)) * 100.0)
print('Test:', np.bincount(test_labels) / float(len(test_labels)) * 100.0)
Dies war ein dummes Beispiel, um die Arbeitsweise der geschichteten Zufallsstichprobe zu testen, da der Iris-Datensatz die gleichen Anteile aufweist, d.h. jede Klasse 50 Items.
Wir werden jetzt mit der Datei strange_flowers.txt des Verzeichnisses data arbeiten. Dieser Datensatz wird im Kapitel Datasets in Python generieren erstellt.
Die Klassen in diesem Datensatz haben eine unterschiedliche Anzahl von Elementen. Zuerst laden wir die Daten:
content = np.loadtxt("data/strange_flowers.txt", delimiter=" ")
data = content[:, :-1] # Letzte Spalte wird abgeschnitten
labels = content[:, -1]
labels.dtype
labels.shape
res = train_test_split(data, labels,
train_size=0.8,
test_size=0.2,
random_state=42,
stratify=labels)
train_data, test_data, train_labels, test_labels = res
# np.bincount expects non negative integers:
print('All:', np.bincount(labels.astype(int)) / float(len(labels)) * 100.0)
print('Training:', np.bincount(train_labels.astype(int)) / float(len(train_labels)) * 100.0)
print('Test:', np.bincount(test_labels.astype(int)) / float(len(test_labels)) * 100.0)
Aufgaben¶
Aufgabe 1¶
In dieser Übung geht es um die Aufteilung von Trainings- und Testdaten auf den Wein-Datensatz von scikit-learn. Der Wein-Datensatz enthält die Ergebnisse einer chemischen Analyse von drei verschiedenen Weinsorten. Jede Probe wird in eine von drei Klassen eingeteilt. Die Aufgabe besteht darin, diesen Datensatz in einen Trainings- und einen Testdatensatz mit einem Verhältnis von 70-30 aufzuteilen, wobei 70% der Daten für das Training und 30% für den Test verwendet werden.
Aufgabe 2¶
Erzeuge nun eine stratifizierte Ausgabe.
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# Load the Wine dataset
wine = load_wine()
X = wine.data
y = wine.target
# Perform train-test split with 70% training and 30% testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Print the shapes of the resulting train and test sets
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
print("y_train shape:", y_train.shape)
print("y_test shape:", y_test.shape)
Lösung zur Aufgabe 2¶
res = train_test_split(X, y,
test_size=0.3,
random_state=42,
stratify=y # i.e. the labels
)
train_data, test_data, train_labels, test_labels = res
# np.bincount expects non negative integers:
print('All:', np.bincount(y.astype(int)) / float(len(y)) * 100.0)
print('Training:', np.bincount(train_labels.astype(int)) / float(len(train_labels)) * 100.0)
print('Test:', np.bincount(test_labels.astype(int)) / float(len(test_labels)) * 100.0)
print("Training set class distribution:")
print({label: count for label, count in zip(wine.target_names,
[sum(train_labels == i) for i in range(len(wine.target_names))])})
print("\nTesting set class distribution:")
print({label: count for label, count in zip(wine.target_names,
[sum(test_labels == i) for i in range(len(wine.target_names))])})
Nächstes Kapitel: Nächste Nachbarn-Klassifikation