

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

Einführung in maschinelles Lernen mit Python¶
Unterschied zwischen "maschinellem Lernen" (Machine Learning) und "Künstlicher Intelligenz" (Artificial Intelligence)¶
Andrew Moore, ehemaliger Dekan der School of Computer Science an der Carnegie Mellon University: "Artificial intelligence is the science and engineering of making computers behave in ways that, until recently, we thought required human intelligence."
Schon die Frage "Was ist Intelligenz?" lässt sich nur schwer beantworten. "Was ist künstliche Intelligenz?" hängt von der Beantwortung der vorigen Frage ab.
Hilfreich ist die Unterteilung in
schwache KI und starke KI
Starke und schwache KI¶
schwache KI:
- beschäftigt sich mit konkreten Anwendungsproblemen
- Unterstüzung des menschlichen Denkens in Teilbereichen
- lernfähig in dem Teilbereich
- kein Bewusstsein
starke KI:
- "allgemeine Intelligenz"
- Vergleichbar mit der menschlichen Intelligenz, muss aber nicht gleich sein, könnte andersartig sein
- logisches Denken
- Kommunikationsfähigkeit, natürliche Sprache
- generell lernfähig
- Bewusstsein?
- Empfindungsvermögen, Emotionen?
- Eigenwahrnehmung?
Starke KI wären Computersysteme, die auf Augenhöhe mit Menschen arbeiten und diese bei schwierigen Aufgaben unterstützen können. Demgegenüber geht es bei schwacher KI darum, konkrete Anwendungsprobleme zu meistern. Das menschliche Denken und technische Anwendungen sollen hier in Einzelbereichen unterstützt werden. Die Fähigkeit zu lernen ist eine Hauptanforderung an KI-Systeme und muss ein integraler Bestandteil von Anfang an sein, d.h. sie darf nicht erst nachträglich hinzugefügt werden. Ein zweites Hauptkriterium ist die Fähigkeit eines KI-Systems, mit Unsicherheit und probabilistischen Informationen umzugehen. Insbesondere sind solche Anwendungen von Interesse, zu deren Lösung nach allgemeinem Verständnis eine Form von „Intelligenz“ notwendig zu sein scheint. Letztlich geht es der schwachen KI somit um die Simulation intelligenten Verhaltens mit Mitteln der Mathematik und der Informatik, es geht ihr nicht um Schaffung von Bewusstsein oder um ein tieferes Verständnis von Intelligenz. Während die Schaffung starker KI an ihrer philosophischen Fragestellung bis heute scheiterte, sind auf der Seite der schwachen KI in den letzten Jahren bedeutende Fortschritte erzielt worden.
in fortschrittliches KI-System muss nicht zwangsläufig viele Ähnlichkeiten mit dem menschlichen Wesen aufweisen. Es wird wahrscheinlich über eine abweichende kognitive Architektur verfügen und in seinen Entwicklungsstadien ebenso wenig mit den evolutionären kognitiven Phasen des menschlichen Denkens vergleichbar sein (Evolution des Denkens). Vor allem ist nicht anzunehmen, dass eine künstliche Intelligenz Gefühle wie Liebe, Hass, Angst oder Freude besitzt. Dennoch kann es ein Verhalten simulieren, das diesen Gefühlen ähnelt.
Was versteht man unter Maschinellem Lernen?¶
Beginnen wir mit einem sehr "alten" Versuch einer Definition von Arthur Samuek, einem IBM-Pionier:
"Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed." ("Maschinelles Lernen: Ein Studienbereich, in dem Computer lernen können, ohne explizit programmiert zu werden.")
Ein guter Versuch, aber es bleiben viele Fragen offen. Unter anderem die Frage, was "Lernen" bedeutet. Fast 40 Jahre später, 1998, prägt Tom Mitchell ein "wohlgestelltes Lernproblem" wiefolgt:
"Well posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.“ (Ein wohlgestelltes Lernproblem: Ein Computerprogramm soll aus Erfahrung E in Bezug auf eine Aufgabe T und ein Leistungsmaß P lernen, wenn sich seine Leistung auf T, gemessen durch P, mit Erfahrung E verbessert.)
(Anmerkung: Ein mathematisches Problem heißt korrekt gestellt (auch wohlgestellt, gut gestellt oder sachgemäß gestellt), wenn folgende Bedingungen erfüllt sind:
- Das Problem hat eine Lösung (Existenz).
- Diese Lösung ist eindeutig bestimmt (Eindeutigkeit).
- Diese Lösung hängt stetig von den Eingangsdaten ab (Stabilität). )
Also, was ist maschinelles Lernen?
Maschinelles Lernen ist der Prozess des automatischen Extrahierens von Wissen aus Daten, normalerweise mit dem Ziel, Vorhersagen über neue, unsichtbare Daten zu treffen. Wie bereits erwähnt, könnte ein Spamfilter mittels eines Klassifikators basierend auf maschinellem Lernen realisiert werden.
Im Zentrum des maschinellen Lernens steht das Konzept, die Entscheidungsfindung aus Daten zu automatisieren, ohne dass der Benutzer explizite Regeln angibt, wie diese Entscheidung getroffen werden soll. Für den Fall von E-Mails gibt der Benutzer keine Liste von Wörtern oder Merkmalen an, die eine E-Mail zu Spam machen. Stattdessen gibt der Benutzer Beispiele für Spam- und Nicht-Spam-E-Mails an, die als solche gekennzeichnet sind. Dabei handelt es sich dann um das sogenannte Lernset.
Das Ziel eines maschinellen Lernmodells ist die Vorhersage neuer, zuvor nicht sichtbarer Daten. In einer realen Anwendung sind wir nicht daran interessiert, eine bereits gekennzeichnete E-Mail als Spam zu markieren oder nicht. Stattdessen möchten wir dem Benutzer das Leben erleichtern, indem wir neue eingehende E-Mails automatisch klassifizieren.
Diese Beispiele werden dann vom Algorithmus gelernt oder trainiert.
Maschinelles Lernen¶
Maschinelles Lernen bedeutet, dass ein Algorithmus (die Maschine) automatisch lernt. Dies bedeutet, dass es in der Lage ist, das notwendige Wissen automatisch aus gegebenen Daten zu extrahieren. Ziel ist es, Vorhersagen für neue, unsichtbare Daten zu treffen. Es gibt eine andere Art, es auszudrücken: In traditionellen heuristischen Entscheidungsalgorithmen legen die Programmierer die Regeln fest, nach denen die Entscheidungen getroffen werden. Beim maschinellen Lernen erfolgt dies unabhängig vom Programm ohne Eingriffe des Menschen!

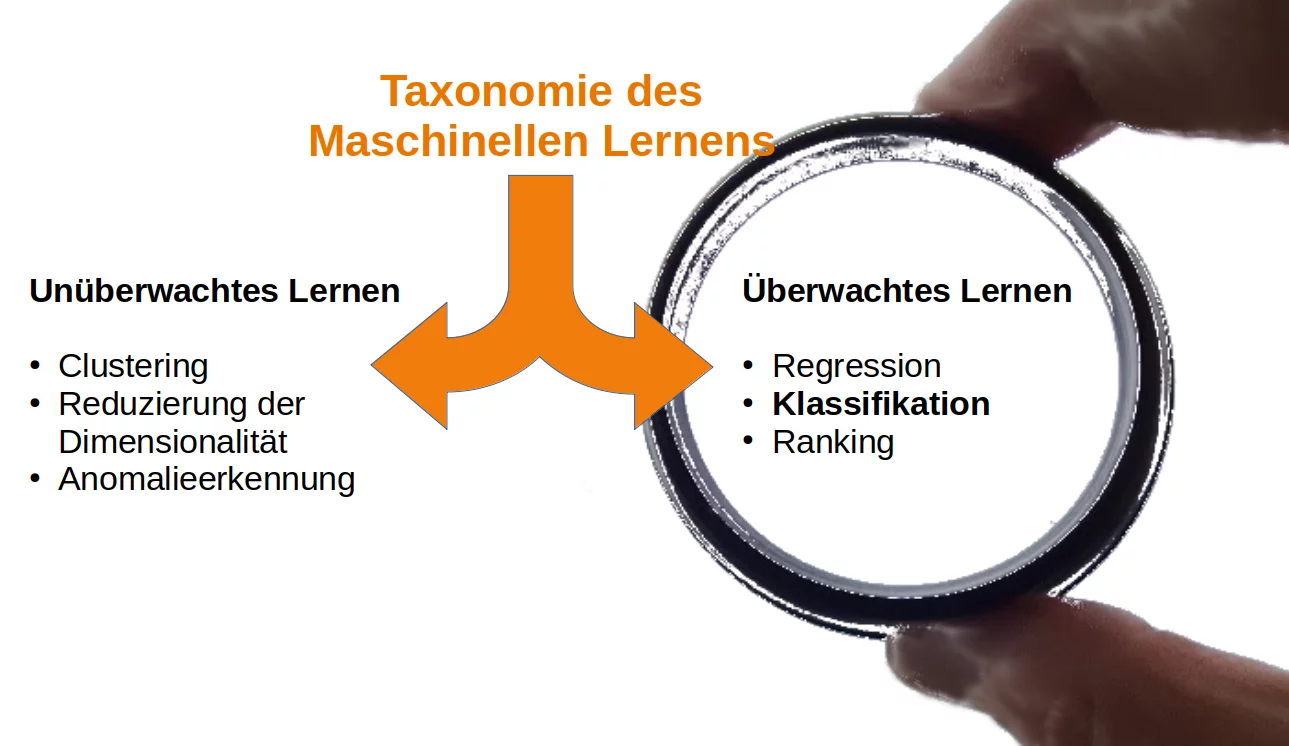
Taxonomie des maschinellen Lernens¶
Es gibt zwei verschiedene Ansätze für maschinelles Lernen:
- Unbeaufsichtigtes Lernen
- Überwachtes Lernen
Wir werden uns ausschließlich mit "überwachtem Lernen in diesem Tutorial" befassen.
Überwachtes Lernen: Klassifikation und Regression¶
Beim überwachten Lernen haben wir einen Datensatz, der sowohl aus Eingabemerkmalen als auch aus einer gewünschten Ergebnis besteht, wie im Beispiel für Spam / No-Spam. Die Aufgabe besteht darin, ein Modell (oder Programm) zu erstellen, das die gewünschte Ausgabe eines unbekannten Objektes vorhersagen kann anhand von Merkmalen.
Einige kompliziertere Beispiele sind:
- Bestimmung eines Zeichen, wenn ein Pixelbild des Zeichens vorliegt.
- Man hat ein Bild eines der Tiere „Hunde“, „Katzen“, „Kühe“, „Schafe“ und möchte nun bestimmen, um welches Tier es sich handelt.
- Personen auf Fotos bestimmen.
- Bestimmen Sie anhand einer Liste von Büchern oder Filmen, welche anderen Bücher oder Filme einer Person gefallen könnten.
Gemeinsam ist diesen Aufgaben, dass es eine oder mehrere unbekannte dem Objekt zuzuordnende Quantitäten gibt, die aus beobachteten Eigenschaften erschlossen werden müssen.
Das überwachte Lernen wird weiter in zwei Kategorien unterteilt:
Klassifikation:

Regression:
Auf den Punkt gebracht: Bei der Klassifizierung geht es um die Vorhersage eines Labels und bei der Regression um die Vorhersage einer Quantität.
Bei der Klassifizierung ist das Label diskret, z. B. "Spam" oder "kein Spam". Mit anderen Worten bietet es eine klare Unterscheidung zwischen Kategorien. Darüber hinaus ist zu beachten, dass Klassenbeschriftungen nominalskalierte Variablen und keine ordinalskalierte Variablen sind. Nominal- und Ordinalvariablen sind beides Unterkategorien von kategorialen Variablen. Ordnungsvariablen entsprechen einer Reihenfolge, zum Beispiel T-Shirt-Größen "XL > L > M > S". Andererseits implizieren nominale Variablen keine Reihenfolge, zum Beispiel können wir (normalerweise) nicht von "orange > blau > grün" ausgehen.
Bei der Regression ist die Bezeichnung fortlaufend, d.h. eine Float-Ausgabe.
Beispielsweise ist die Aufgabe, festzustellen, welches Tier („Hund“, „Katze“, „Kuh“, „Schaf“) in einem Bild dargestellt ist, ein Klassifizierungsproblem, d.h. vier verschiedene Kategorien. Auf der anderen Seite könnten wir das Alter eines Objekts anhand einiger Beobachtungen abschätzen wollen: Dies wäre ein Regressionsproblem. weil das Etikett (Alter) eine kontinuierliche Größe ist.
Beim überwachten Lernen wird immer zwischen einem Trainingssatz (Lernset), für den das gewünschte Ergebnis angegeben bzw. bekannnt ist, und einem Testsatz unterschieden, für den das gewünschte Ergebnis abgeleitet oder berechnet werden muss. Das Lernmodell passt das Vorhersagemodell an den Trainingssatz an, und wir verwenden den Testsatz, um seine Generalisierungsleistung zu bewerten.
Unüberwachtes Lernen¶
Beim "Unüberwachten Lernen" ist den Daten keine gewünschte Ausgabe zugeordnet. Stattdessen sind wir daran interessiert, irgendeine Form von Wissen oder Modell aus den gegebenen Daten zu extrahieren. In gewissem Sinne können Sie sich unbeaufsichtigtes Lernen als Mittel vorstellen, um Labels (Etiketten) aus den Daten selbst zu entdecken. Unüberwachtes Lernen ist oft schwieriger zu verstehen und zu bewerten.
Unbeaufsichtigtes Lernen umfasst Aufgaben wie Dimensionsreduktion, Clustering und Dichteschätzung. Zum Beispiel können wir in den oben diskutierten Irisdaten unbeaufsichtigte Methoden verwenden, um Kombinationen der Messungen zu bestimmen, die die Struktur der Daten am besten darstellen. Wie wir unten sehen werden, kann eine solche Projektion der Daten verwendet werden, um den vierdimensionalen Datensatz in zwei Dimensionen zu visualisieren. Einige weitere unbeaufsichtigte Lernprobleme sind:
- Bestimmen Sie anhand detaillierter Beobachtungen entfernter Galaxien, welche Merkmale oder Merkmalskombinationen die Informationen am besten zusammenfassen.
- Trennen Sie eine Mischung aus zwei Schallquellen (z. B. eine Person spricht, während Musik spielt)
- Isolieren Sie in einem gegebenen Video ein sich bewegendes Objekt und kategorisieren Sie es in Bezug auf andere sich bewegende Objekte, die gesehen wurden.
- Bei einer großen Sammlung von Nachrichtenartikeln finden Sie in diesen Artikeln wiederkehrende Themen.
- Bei einer bestimmten Bildersammlung werden ähnliche Bilder zu einem Cluster zusammengefasst (um sie beispielsweise bei der Visualisierung einer Sammlung zu gruppieren).
Manchmal können die beiden sogar kombiniert werden: z. Unbeaufsichtigtes Lernen kann verwendet werden, um nützliche Merkmale in heterogenen Daten zu finden, und diese Merkmale können dann in einem überwachten Rahmen verwendet werden.
Beispiele für maschinelles Lernen¶
- Spam Filter: Der Algorithmus lernt ein Vorhersagemodell aus Daten, die als "Spam" und "kein Spam" (ham) gekennzeichnet sind. Nach dem Training kann für neue E-Mails vorhergesagt werden, ob es sich um Spam handelt oder nicht.
- Zeichenerkennung
- Objekterkennung in Bildern
- und viele mehr
Wie bereits erwähnt, könnte ein Spamfilter unter Verwendung eines Klassifikators implementiert werden, der auf maschinellem Lernen basiert.
Im Zentrum des maschinellen Lernens steht das Konzept der Automatisierung der Entscheidungsfindung aus Daten, ohne dass der Benutzer explizite Regeln für die Entscheidungsfindung festlegt. Bei E-Mails stellt der Benutzer keine Liste von Wörtern oder Funktionen bereit, die eine E-Mail als Spam auszeichnen. Stattdessen stellt der Benutzer Beispiele für Spam- und Nicht-Spam-E-Mails bereit, die als solche gekennzeichnet sind. Dies ist das sogenannte Lernset.
Ziel eines maschinellen Lernmodells ist es, neue, bisher unsichtbare Daten vorherzusagen. In einer realen Anwendung sind wir nicht daran interessiert, eine bereits markierte E-Mail als Spam zu markieren oder nicht. Stattdessen möchten wir den Benutzern das Leben erleichtern, indem wir neue eingehende E-Mails automatisch klassifizieren.
Diese Beispiele werden dann vom Algorithmus gelernt oder trainiert:
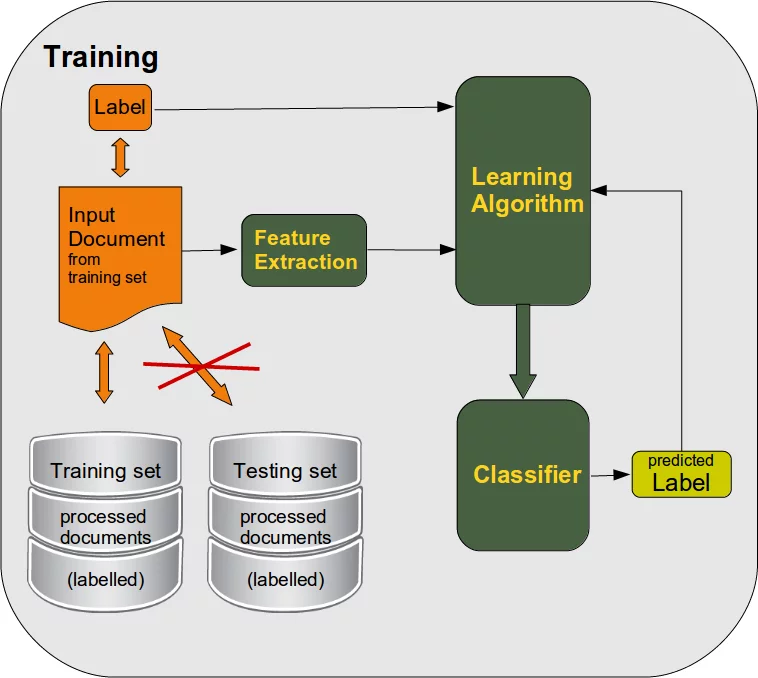
Nach der Lernphase müssen wir den Klassifikator bewerten. Wir testen sowohl an gekennzeichneten Lerndaten als auch an nicht erlernten gekennzeichneten Testdaten:
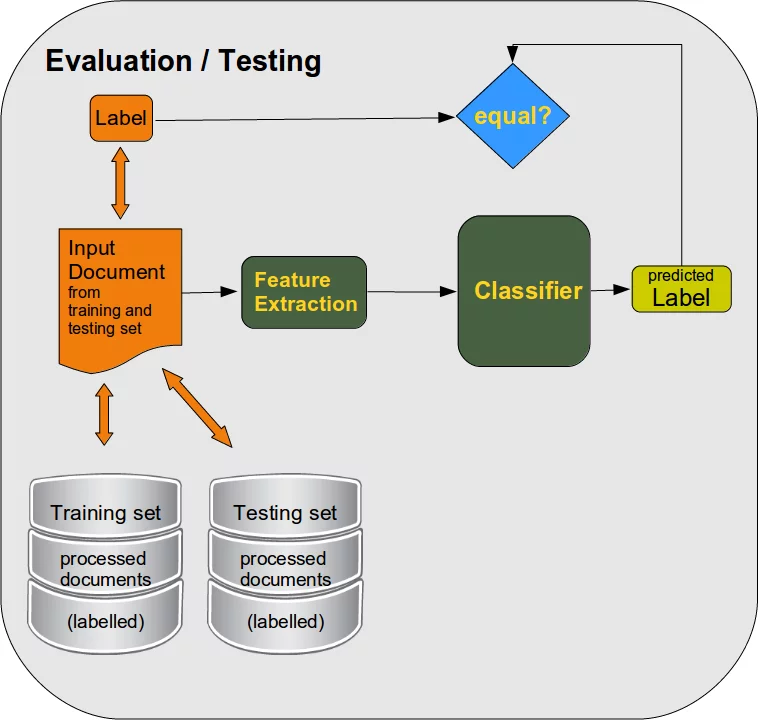
Wenn wir mit den Ergebnissen zufrieden sind, kann der Klassifizierer völlig unbekannte, also bisher nicht gelernte, Dokumente klassifizieren:
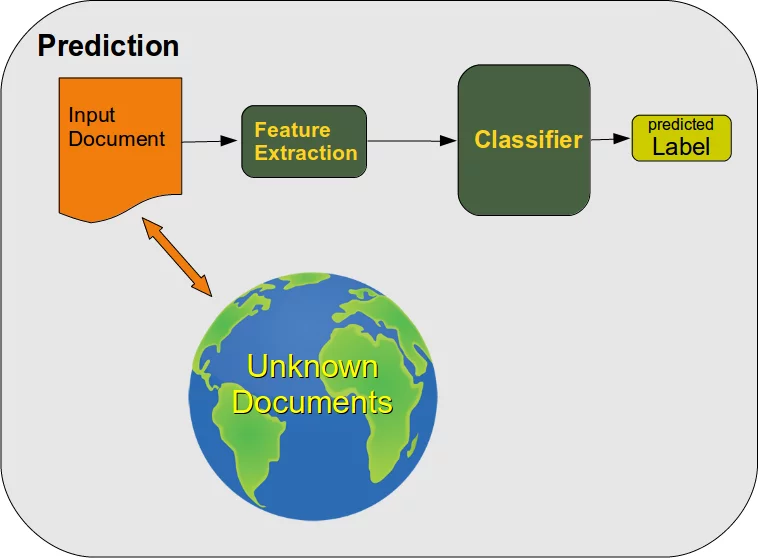
Die Daten werden dem Algorithmus normalerweise als zweidimensionales Array (oder Matrix) von Zahlen präsentiert. Jeder Datenpunkt (auch als Training oder Trainingsinstanz bezeichnet), von dem wir entweder lernen oder eine Entscheidung treffen möchten, wird als eine Liste von Zahlen dargestellt, ein sogenannter Merkmalsvektor, und seine enthaltenen Merkmale repräsentieren die Eigenschaften dieses Objektes.