

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen


Mengen
Einführung
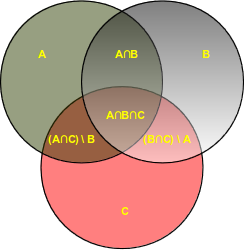 Auch wenn die Mengenlehre über lange Zeit heftig kritisiert und immer noch kritisiert wird, ist sie ein
wesentliches Gebiet der Mathematik. Die heutige Mathematik ist in der Terminologie der Mengenlehre formuliert
und baut auf deren Axiomen auf. Die Mengenlehre ist noch ein recht junges Gebiet der Mathematik.
Der deutsche Mathematiker Georg Cantor (1845 - 1918) begründete die Mengenlehre mit seinem 1874
erschienenen Artikel "Über eine Eigenschaft des Inbegriffes aller reellen algebraischen Zahlen".
Anfangs also bis ins Jahr 1877 bezeichnete er übrigens noch die Mengenlehre als "Mannigfaltigkeitslehre".
Auch wenn die Mengenlehre über lange Zeit heftig kritisiert und immer noch kritisiert wird, ist sie ein
wesentliches Gebiet der Mathematik. Die heutige Mathematik ist in der Terminologie der Mengenlehre formuliert
und baut auf deren Axiomen auf. Die Mengenlehre ist noch ein recht junges Gebiet der Mathematik.
Der deutsche Mathematiker Georg Cantor (1845 - 1918) begründete die Mengenlehre mit seinem 1874
erschienenen Artikel "Über eine Eigenschaft des Inbegriffes aller reellen algebraischen Zahlen".
Anfangs also bis ins Jahr 1877 bezeichnete er übrigens noch die Mengenlehre als "Mannigfaltigkeitslehre".
1895 gab er folgende Definition einer Menge: "Unter einer 'Menge' verstehen wir jede Zusammenfassung M von bestimmten wohlunterschiedenen Objekten m unserer Anschauung oder unseres Denkens (welche die 'Elemente' von M genannt werden) zu einem Ganzen."
Eine Menge kann beliebige Elemente enthalten: zum Beispiel Zahlen, Zeichen, Buchstaben, Wörter, Namen oder sogar andere Mengen. Eine Menge wird in der Mathematik üblicherweise mit einem Großbuchstaben bezeichnet.
Mengen in Python
Der Datentyp set", der ein sogenannter "collection"-Typ ist, ist in Python seit Version 2.4. enthalten. Ein set enthält eine ungeordnete Sammlung von einmaligen und unveränderlichen Elementen. In anderen Worten: Ein Element kann in einem set-Objekt nicht mehrmals vorkommen, was bei Listen und Tupel jedoch möglich ist. Beim Datentyp set handelt es sich um die Python-Implementierung von Mengen, wie sie aus der Mathematik bekannt sind.Sets erzeugen
Will man eine Menge erzeugen, kann man dies mit der eingebauten (built-in) Funktion set tun. Dazu wird die Funkton set auf ein iterierbares Objekt, wie eine Liste oder ein Tupel angewendet.Im folgenden Beispiel wird ein String in seine Zeichen vereinzelt um die folgende Menge zu generieren:
>>> x = set("A Python Tutorial")
>>> x
set(['A', ' ', 'i', 'h', 'l', 'o', 'n', 'P', 'r', 'u', 't', 'a', 'y', 'T'])
>>> type(x)
<type 'set'>
>>>
Im folgenden sehen wir, wie dies mit einer Liste funktioniert:
>>> x = set(["Perl", "Python", "Java"]) >>> x set(['Python', 'Java', 'Perl']) >>>
Nun wollen wir zeigen, was passiert, wenn wir ein tuple mit wiederholt auftrenden Elementen an die set-Funktion übergeben - in unserem Beispiel tritt die Stadt Paris mehrmals auf:
>>> cities = set(("Paris", "Lyon", "London","Berlin","Paris","Birmingham"))
>>> cities
set(['Paris', 'Birmingham', 'Lyon', 'London', 'Berlin'])
>>>
Wie erwartet, gibt es keine doppelten Einträge in unserer resultierenden Menge.
Unveränderliche Mengen / Immutable Sets
Sets sind so implementiert, dass sie keine veränderlichen (mutable) Objekte erlauben. Das folgende Beispiel demonstriert, dass wir beispielsweise keine Listen als Elemente haben können:
>>> cities = set((("Python","Perl"), ("Paris", "Berlin", "London")))
>>> cities = set((["Python","Perl"], ["Paris", "Berlin", "London"]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>>
Frozensets
Auch wenn sets keine veränderlichen Elemente enthalten können, sind sie selbst veränderlich. Wir können zum Beispiel neue Element einfügen:
>>> cities = set(["Frankfurt", "Basel","Freiburg"])
>>> cities.add("Strasbourg")
>>> cities
set(['Freiburg', 'Basel', 'Frankfurt', 'Strasbourg'])
>>>
Frozensets sind wie sets, aber sie können nicht verändert werden. Sie sind also unveränderlich (immutable):
>>> cities = frozenset(["Frankfurt", "Basel","Freiburg"])
>>> cities.add("Strasbourg")
Traceback (most recent call last):
File "<stdin&module>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'
>>>
Vereinfachte Notation
Mengen kann man auch ohne Benutzung der built-in-Funktion "set" definieren. Dazu benutzt man einfach die geschweiften Klammern:
>>> adjectives = {"cheap","expensive","inexpensive","economical"}
>>> adjectives
set(['inexpensive', 'cheap', 'expensive', 'economical'])
>>>
Operationen auf "set"-Objekten
add(element)
- Mit der Methode add fügt man ein Objekt in eine Menge als neues Element ein, falls es noch nicht
vorhanden ist. Es gilt zu beachten,
dass es sich dabei um eine unveränderliches Element handelt.
Im folgenden Beispiel fügen wir einen String ein:
>>> colours = {"red","green"} >>> colours.add("yellow") >>> colours set(['green', 'yellow', 'red']) >>> colours.add(["black","white"]) Traceback (most recent call last): File "<stdin&module>", line 1, in <module> TypeError: unhashable type: 'list' >>>Selbstverständlich wird ein Objekt nur dann als neues Element eingefügt, wenn es noch nicht enthalten ist. Ist es bereits enthalten, hat der Aufruf der Methode keine Auswirkungen. clear()
- Alle Elemente einer Menge werden entfernt. Die Menge ist also anschließend leer, wie wir im
folgenden Beispiel sehen:
>>> cities = {"Stuttgart", "Konstanz", "Freiburg"} >>> cities.clear() >>> cities set([]) >>> copy
-
copy erzeugt eine flache Kopie einer Menge, die zurückgeliefert wird. Wir demonstrieren
die Benutzung anhand eines Beispiels:
>>> more_cities = {"Winterthur","Schaffhausen","St. Gallen"} >>> cities_backup = more_cities.copy() >>> more_cities.clear() >>> cities_backup set(['St. Gallen', 'Winterthur', 'Schaffhausen']) >>>
Nur für diejenigen, die glauben, dass eine einfache Zuweisungen auch genügen könnte:>>> more_cities = {"Winterthur","Schaffhausen","St. Gallen"} >>> cities_backup = more_cities >>> more_cities.clear() >>> cities_backup set([]) >>>Die Zuweisung "cities_backup = more_cities" erzeugt nur einen Pointer, d.h. einen weiteren Namen für das gleiche Objekt. difference()
-
Diese Methode liefert die Differenz von zwei oder mehr Mengen zurück. Wir illustrieren dies wie
immer an einem Beispiel:
>>> x = {"a","b","c","d","e"} >>> y = {"b","c"} >>> z = {"c","d"} >>> x.difference(y) set(['a', 'e', 'd']) >>> x.difference(y).difference(z) set(['a', 'e']) >>>Statt die Methode difference zu benutzen, hätten wir auch den Operator "-" benutzen können:>>> x - y set(['a', 'e', 'd']) >>> x - y - z set(['a', 'e']) >>>
difference_update()
-
Die Methode difference_update entfernt alle Element einer anderen Menge aus einer Menge.
"x.difference_update()" ist gleichbedeutend mit "x = x - y"
>>> x = {"a","b","c","d","e"} >>> y = {"b","c"} >>> x.difference_update(y) >>> >>> x = {"a","b","c","d","e"} >>> y = {"b","c"} >>> x = x - y >>> x set(['a', 'e', 'd']) >>> discard(el)
- Das Element el wird aus einer Menge entfernt, falls es enthalten ist.
Falls el nicht in der Menge enthalten ist, passiert nichts.
>>> x = {"a","b","c","d","e"} >>> x.discard("a") >>> x set(['c', 'b', 'e', 'd']) >>> x.discard("z") >>> x set(['c', 'b', 'e', 'd']) >>> remove(el)
- funktioniert wie discard(), aber falls el nicht in der Menge enthalten ist, wird ein Fehler generiert, d.h. ein KeyError:
>>> x = {"a","b","c","d","e"} >>> x.remove("a") >>> x set(['c', 'b', 'e', 'd']) >>> x.remove("z") Traceback (most recent call last): File "<stdin&module>", line 1, in <module> KeyError: 'z' >>> intersection(s)
-
Liefert die Schnittmenge von s und der Instanzmenge zurück.
>>> x = {"a","b","c","d","e"} >>> y = {"c","d","e","f","g"} >>> x.intersection(y) set(['c', 'e', 'd']) >>>Dies kann auch mit dem "&"-Zeichen formuliert werden:>>> x = {"a","b","c","d","e"} >>> y = {"c","d","e","f","g"} >>> x.intersection(y) set(['c', 'e', 'd']) >>> >>> x = {"a","b","c","d","e"} >>> y = {"c","d","e","f","g"} >>> x & y set(['c', 'e', 'd']) >>> isdisjoint()
- Diese Methode liefert True zurück, wenn zwei Mengen eine leere Schnittmenge haben.
issubset()
-
x.issubset(y) liefert True zurück, falls x eine Untermenge von y ist.
"<=" kann statt dem Aufruf der Methode verwendet werden. ">" prüft, ob es sich um eine echte Obermenge handelt: Wenn x > y gilt, dann enthält x mindestens ein Element, dass nicht in y enthalten ist.
>>> x = {"a","b","c","d","e"} >>> y = {"c","d"} >>> x.issubset(y) False >>> y.issubset(x) True >>> x < y False >>> y < x # y ist eine echte Untermenge von y True >>> x < x # eine Menge kann nie eine echte Untermenge ihrerselbst sein. False >>> x <= x True >>> issuperset()
-
x.issuperset(y) liefert True zurück, falls x eine Obermenge von y ist.
">=" kann statt dem Aufruf der Methode verwendet werden. ">" kann genutzt werden zu testen, ob es sich um eine echte Obermenge handelt: Wenn x > y gilt, dann enthält x mindestens ein Element, dass nicht in y enthalten ist.
>>> x = {"a","b","c","d","e"} >>> y = {"c","d"} >>> x.issuperset(y) True >>> x > y True >>> x >= y True >>> x >= x True >>> x > x False >>> x.issuperset(x) True >>> pop()
- pop() liefert ein beliebiges Element der Menge zurück. Dieses Element wird dabei
aus der Menge entfernt. Die Methode erzeugt einen KeyError, falls die Menge leer ist.
>>> x = {"a","b","c","d","e"} >>> x.pop() 'a' >>> x.pop() 'c'