Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

Fork und Prozesse
Fork
 Schon lange vor der Biologie hat sich die Informatik mit dem Klonen beschäftigt. Aber man
nannte es nicht klonen sondern forken.
Schon lange vor der Biologie hat sich die Informatik mit dem Klonen beschäftigt. Aber man
nannte es nicht klonen sondern forken.
fork bedeutet in Englisch Gabel, Gabelung, Verzweigung und als Verb gabeln, aufspalten
und verzweigen. Aber es bedeutet auch eine Aufspaltung oder als Verb aufspalten. Im letzeren
Sinn wird es bei Betriebssystemen, vor allem bei Unix und Linux verwendet.
Prozesse werden mittels des Kommandos "fork" aufgespalten - geklont würde man heute wohl eher sagen - und
führen dann ein eigenständiges "Leben".
In der Informatik steht der Begriff Fork zur Bezeichnung verschiedener Sachverhalte:
- Ein vom Betriebssystem bereitgestellter Systemaufruf, der den bestehenden Prozess aufspaltet - und dabei eine exakte Kopie des Prozesses erzeugt - und dann beide Prozesse gewissermaßen parallel laufen lässt.
- In der Softwareentwicklung bezeichnet ein Fork eine Abspaltung von einem (Haupt-)Projekt.
- Die Fähigkeit einiger Dateisysteme zur Unterteilung von Dateien
Fork in Python
Beim Systemaufruf fork() erzeugt der aktuelle Prozess eine Kopie von sich selbst, welche dann als Kindprozess des erzeugenden Programmes läuft. Der Kindprozess übernimmt die Daten und den Code vom Elternprozess und erhält vom Betriebssystem eine eigene Prozessnummer, die PID (engl. "Process IDentifier"). Der Kindprozess läuft als eigenständige Instanz des Programms, unabhängig vom Elternprozess. Am Rückgabewert von fork() erkennt man, in welchem Prozess man sich befindet. 0 kennzeichnet den Kindprozess und ein positiver Rückgabewert steht für den Elternprozess. Im Fehlerfall liefert fork() einen Wert kleiner 0 und kein Kindprozess wird erzeugt.Um Prozesse forken zu können, müssen wir das Modul os in Python importieren.
Das folgende Beispiel-Skript zeigt einen Eltern-Prozess (Parent), der sich beliebig oft forken kann, solange man als Benutzer des Skriptes kein q bei der Eingabeaufforderung eingibt. Sowohl der Kindprozess als auch der Elternprozess machen nach dem fork mit der if-Anweisung weiter. Im Elternprozess hat newpid einen von 0 verschiedenen Wert, während newpid im Kindprozess den Wert 0 hat, so dass im Kindprozess die Funktion child() aufgerufen wird. Die exit-Anweisung
os.exit(0) in der child-Funktion
ist notwendig, da sonst der Kindprozess in den Elternprozess zurückkehren würde und zwar zum raw_input().
import os
def child():
print('\nA new child ', os.getpid())
os._exit(0)
def parent():
while True:
newpid = os.fork()
if newpid == 0:
child()
else:
pids = (os.getpid(), newpid)
print("parent: %d, child: %d\n" % pids)
reply = input("q for quit / c for new fork")
if reply == 'c':
continue
else:
break
parent()
Unabhängige Programme durch fork() starten
Bisher haben die Kindprozesse in den Beispielen eine Funktion innerhalb des Skriptes selbst aufgerufen und haben sich dann beendet.Forks werden aber häufig genutzt, um unabhängig laufende Programme zu starten. Dazu gibt es im Modul os die exec*()-Funktionen.
Sie führen ein neues Programm aus, indem sie den aktuellen Prozess damit ersetzen. Sie kehren nicht in das aufrufende Programm zurück. Sie erhalten unter Unix/Linux sogar die gleich Prozess-ID, als das aufrufende Programm.
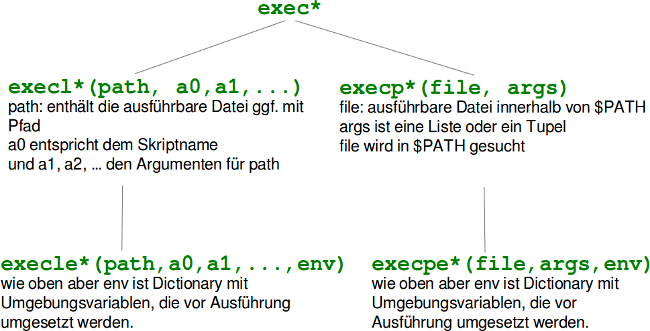
Die exec*()-Funktionen
Die exec*()-Funktionen gibt es in verschiedenen Variationen:- os.execl(path, arg0, arg1, ...)
- os.execle(path, arg0, arg1, ..., env)
- os.execlp(file, arg0, arg1, ...)
- os.execlpe(file, arg0, arg1, ..., env)
- os.execv(path, args)
- os.execve(path, args, env)
- os.execvp(file, args)
- os.execvpe(file, args, env)
Für unsere Beispiele wollen wir das folgende Bash-Shell-Skript nutzen, dass wir unter test.sh abspeichern. Wir haben es im Verzeichnis /home/bernd/bin2 abgespeichert. Zum Verständnis der folgenden Beispiele ist es lediglich wichtig, dass test.sh nicht in einem Verzeichnis liegt, das sich in $PATH befindet. Außerdem sollte test.sh ausführbar sein. Also folgenden Shell-Befehl ausführen:
chmod 755 test.sh#!/bin/bash script_name=$0 arg1=$1 current=`pwd` echo $script_name, $arg1 echo "XYZ: "$XYZ echo "PATH: "$PATH echo "current directory: $current"In einem anderen Verzeichnis, z.B. /home/bernd/python, haben wir ein Python-Skript execvp.py, dass dieses Bash-Skript aufruft:
#!/usr/bin/python
import os
args = ("test","abc")
os.execvp("test.sh", args)
Da test.sh nicht in $PATH ist, gibt es eine Fehlermeldung, wenn man execvp in der Kommandozeile aufruft:
$ ./execvp.py
Traceback (most recent call last):
File "./execvp.py", line 6, in <module>
os.execvp("test.sh", args)
File "/usr/lib/python2.6/os.py", line 344, in execvp
_execvpe(file, args)
File "/usr/lib/python2.6/os.py", line 380, in _execvpe
func(fullname, *argrest)
OSError: [Errno 2] No such file or directory
Damit diese Fehlermeldung nicht erfolgt und unser Shell-Skript gefunden werden kann, erweitern wir die
PATH-Umgebungsvariable um das Verzeichnis, in dem test.sh steht, also in unserem Fall /home/bernd/bin2:
$ PATH=$PATH:/home/bernd/bin2 $ ./execvp.py /home/bernd/bin2/test.sh, abc XYZ: PATH: /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/bin:/home/bernd/bin:/home/bernd/bin2 current directory: /home/bernd/pythonEine andere elegante Möglichkeit den Pfad zu erweitern bietet die execvpe()-Funktion. Ihr kann man als drittes Argument ein Dictionary mit Umgebungsvariablen mitgeben. Die Umgebungsvariablen werden durch die Werte in diesem Dictionary ersetzt:
import os
env = {"PATH":"/home/bernd/bin2", "XYZ":"BlaBla"}
args = ("test","abc")
os.execvpe("test.sh", args, env)
Speichern wir obiges Skript in execvpe.py, erhalten wir auf der Shell beim Start folgende Ergebnisse:
$ ./execvpe.py /home/bernd/bin2/test.sh, abc XYZ: BlaBla PATH: /home/bernd/bin2/ current directory: /home/bernd/python/ $Im vorigen Beispiel wird der Wert der Shell-Umgebungsvariablen $PATH durch den neuen Wert im Dictionary überschrieben. Will man das vermeiden, d.h. das neue Verzeichnis nur anhängen, muss man den Code wie folgt ändern:
import os
path = os.environ["PATH"] + ":/home/bernd/bin2/"
env = {"PATH":path, "XYZ":"BlaBla"}
os.execlpe("test.sh", "test","abc", env)
Will man execlpe() statt execvpe() benutzen, so muss man das Python-Skript wie
folgt ändern:
import os
env = {"PATH":"/home/bernd/bin2/", "XYZ":"BlaBla"}
os.execlpe("test.sh", "test","abc", env)
Übersichtsbild der exec-Funktionen