

 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen
 Buch kaufen
Buch kaufen

Nächstes Kapitel: Reguläre Ausdrücke für Fortgeschrittene
Reguläre Ausdrücke
In diesem Kapitel unseres Python-Tutorials möchten wir eine detaillierte und
anschauliche Einführung in die regulären Ausdrücke ganz allgemein aber vor
allen Dingen auch unter Python3 bieten.
Der Begriff "Regulärer Ausdruck" kommt aus der Automatentheorie und der Theorie der formalen Sprachen, zwei Gebiete der theoretischen Informatik.
Als Erfinder der regulären Sprachen gilt der amerikanische Mathematiker Stephen Cole Kleene, der in den 1950er Jahren reguläre Mengen einführte.
In der theoretischen Informatik dienen reguläre
Ausdrücke zur formalen Definition einer Sprachfamilie mit bestimmten Eigenschaften, die sogenannten
regulären Sprachen. Zu jedem regulären Ausdruck existiert ein endlicher Automat
(Implementierung eines endlichen Automaten in Python),
der die von dem Ausdruck spezifizierte Sprache akzeptiert.
In Programmiersprachen werden reguläre Ausdrücke meist zur Filterung von Texten oder Textstrings genutzt, d.h. sie erlauben einem zu prüfen, ob ein Text oder ein String zu einem RA "matched", d.h. zutrifft, übereinstimmt oder passt.
RA finden auch Verwendung, um Textersetzungen, die recht komplex sein können, durchzuführen.
Einen äußerst interessanten Aspekt von regulären Ausdrücken möchten wir nicht unerwähnt lassen:
Die Syntax der regulären Ausdrücke ist in allen Programmiersprachen und Skriptsprachen gleich, also
z.B. in Python, Perl, Java, SED, AWK oder auch in C#. außerdem werden sie von vielen Texteditoren, wie zum Beispiel dem vi benutzt.
Einführung
In unserer Einführung über sequentielle Datentypen lernten Sie den "in" Operator kennen.>>> s = "Reguläre Ausdrücke einfach erklärt!" >>> "einfach" in s True >>>Im obigen Beispiel wurde geprüft, ob das Wort "einfach" im String s vorkommt.
Im folgenden zeigen wir Schritt für Schritt, wie die Stringvergleiche durchgeführt werden.
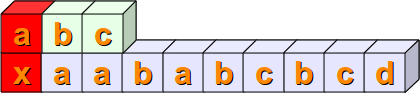
In dem String s = "xaababcbcd"
soll geprüft werden ob der Substring sub = "abc"
vorkommt. Übrigens handelt es sich bei einem Substring bereits um einen regulären Ausdruck, wenn auch ein besonders einfacher.
Zuerst wird geprüft, ob die ersten Positionen übereinstimmen, also s[0] == sub[0]. Dies ist in unserem Beispiel nicht erfüllt, was wir durch die Farbe Rot kenntlich machen:
Nun wird geprüft, ob gilt s[1:4] == sub. Dazu wird erst geprüft, ob sub[0] == s[1] erfüllt ist. Dies gilt, was wir mit der Farbe Grün kenntlich machen. Dann wird weiter verglichen, aber s[2] ist ungleich sub[1]:
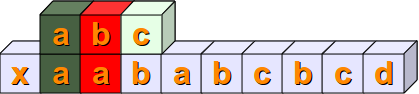
Nun vergleichen wir s[2:5] mit sub. In diesem Fall stimmen sogar die ersten beiden Positionen des Substrings überein.
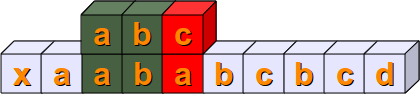
Für den nächsten Schritte benötigen wir wohl keine Erklärung mehr:
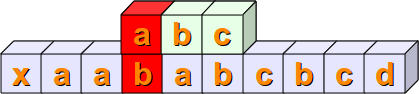
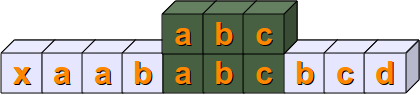
Im nächsten Schritt kann eine vollständige Übereinstimmung gefunden werden, denn es gilt s[4:7] == sub
Das re-Modul
Im vorigen Abschnitt sagten wir bereits, dass man sub bereits als einen einfachen regulären Ausdruck auffassen kann.Um mit Python mit regulären Ausdrücken arbeiten zu können, muss man erst das Modul re importieren. re ist eine Standardbibliothek, die zahlreiche Funktionen und Methoden zum Arbeiten mit regulären Ausdrücken zur Verfügung stellt.
Darstellung von regulären Ausdrücken in Python
Innerhalb von regulären Ausdrücken haben zahlreiche Zeichen Sonderbedeutungen, so wie auch der Backslash (Rückwärtsschrägstrich). Prinzipiell werden reguläre Ausdrücke in Python als Strings dargestellt. Bei Strings werden aber Backslashes als Escape-Zeichen benutzt. Das bedeutet aber, dass sie aus unserem regulären Ausdruck entfernt werden, bzw. mit dem folgenden Zeichen einer Sonderbedeutung zugeführt werden. Man kann dies verhindern, indem man jeden Backslash eines regulären Ausdrucks als "\\" schreibt, was aber die Gefahr birgt, dass man es öfters vergisst und die Ausdrücke komplizierter zu verstehen sind. Die beste Lösung besteht darin, Raw-Strings zu verwenden, also einen String mit einem vorgestellten r zu markieren:r"^a.*\.html$"
Wir werden die Elemente des obigen regulären Ausdruck noch im Detail besprechen, aber um Sie nicht im Dunkeln zu lassen: Dieser Ausdruck passt auf alle Dateinamen (Strings), die mit einem kleinen "a" beginnen und mit ".html" enden.
Syntax der regulären Ausdrücke
r"cat" ist ein regulärer Ausdruck. Er gehört zu den wohl am einfachsten zu verstehenden
Ausdrücken, denn er enthält keinerlei Metazeichen (Funktionszeichen) mit Sonderbedeutungen.
Unser Beispielausdruck r"cat" matched beispielsweise die folgende Zeichenkette:
"A cat and a rat can't be friends."
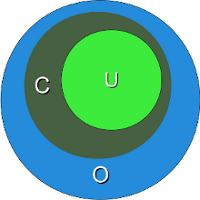
Interessanterweise zeigt sich schon in diesem ersten Beispiel ein "beliebter" Fehler. Eigentlich will man Strings matchen, in denen das Wort cat vorkommt. Dies gelingt auch, aber man erhält auch beispielsweise "cats", was möglicherweise noch erwünscht ist, da es ja der Plural von cat ist. Schlimmer sind jedoch eine ganze Menge zusätzlicher Wörter, in denen die Buchstabenfolge "cat" als Teilstring vorkommt, also auch Wörter wie "education", "communicate", "falsification", "ramifications", "cattle" und viele andere, die überhaupt nichts mit "Katzen" zu tun haben. Dies ist ein Fall von "over matching", d.h. wir erhalten positive Ergebnisse, die nicht gewünscht sind.
Wir haben dies im nebenstehenden Diagramm mengenmäßig veranschaulicht. Der dunkelgrüne Kreis C entspricht der Menge, die wir gerne erkennen wollen, aber wir erkennen die Menge O (blauer Kreis). C ist eine Teilmenge von O. In diesem Diagramm erkennt man auch eine Menge U (hellgrüner Kreis), die eine Teilmenge unserer gewünschten Menge C ist. Dies ist ein Fall von "under matching". Ein Beispiel hierfür wäre, wenn wir versuchen unseren regulären Ausdruck zu verbessern. Wir könnten auf die Idee kommen vor und hinter dem Wort cat im regulären Ausdruck ein Leerzeichen einzufügen, also
r" cat "
Durch diese Änderung würden wir nicht mehr auf Wörter wie "education", "falsification" und
"rammification" hereinfallen. Wie sieht es aber mit einem String
"The cat, called Oscar, climbed on the roof." aus? Er wird nun als nicht mehr passend eingestuft.
Diese Problematik wird im folgenden noch klarer. Zunächst wollen wir uns jedoch mal anschauen, wie man reguläre Ausdrücke in Python überprüfen kann. Dann sind wir auch in der Lage die folgenden Beispiele direkt in Python nachzuvollziehen.
>>> import re
>>> x = re.search("cat","A cat and a rat can't be friends.")
>>> print(x)
<_sre.SRE_Match object; span=(2, 5), match='cat'>
>>> x = re.search("cow","A cat and a rat can't be friends.")
>>> print(x)
None
>>>
Im vorigen Beispiel haben wir die Methode search aus dem re-Modul verwendet. Es ist wohl die am
wichtigsten und am häufigsten benutzte Methode. Mittels search(expr,s) wird ein String s nach dem
Vorkommen eines Teilstrings untersucht, der auf den regulären Ausdruck expr passt. Der erste gefundene
Teilstring wird zurückgeliefert. Wenn wir das Ergebnis ausdrucken, sehen wir, dass im positiven Fall
ein sogenanntes Match-Objekt zurückgegeben wird, während im negativen Fall ein "None" zurückgegeben
wird. Mit diesem Wissen kann man reguläre Ausdrücke bereits in einem Python-Skript nutzen, ohne Näheres
über die Match-Objekte zu wissen:
>>> if re.search("cat","A cat and a rat can't be friends."):
... print("Der Ausdruck hat gepasst")
... else:
... print("Der Ausdruck hat NICHT gepasst")
...
Der Ausdruck hat gepasst
>>> if re.search("cow","A cat and a rat can't be friends."):
... print("Der Ausdruck hat gepasst")
... else:
... print("Der Ausdruck hat NICHT gepasst")
...
Der Ausdruck hat NICHT gepasst
>>>
Beliebiges Zeichen
Nehmen wir an, dass wir im vorigen Beispiel nicht daran interessiert sind, das Wort cat zu finden, sondern dreibuchstabige Wörter, die mit "at" enden.Die regulären Ausdrücke bieten einen Metacharacter ".", der als Platzhalter für ein beliebiges Zeichen steht. Den regulären Ausdruck könnte man so formulieren:
r" .at "
Der reguläre Ausdruck matched nun durch Blank isolierte dreibuchstabige Wörter, die mit "at" enden. Nun erhalten wir Wörter wie "rat", "cat", "bat", "eat", "sat" und andere.
Aber was, wenn im Text ein "@at" oder "3at" stehen würde? Die matchen dann auch und wir haben wieder ein over matching. Eine Lösung, um dies zu umgehen, lernen wir im nun folgenden Unterabschnitt unserer Einführung in die regulären Ausdrücke unter Python kennen.
Zeichenauswahl
Durch eckige Klammern "[" und "]" können wir eine Zeichenauswahl definieren . Der Ausdruck in eckigen Klammern steht dann für genau ein Zeichen aus dieser Auswahl. Betrachten wir den folgenden regulären Ausdruck:r"M[ae][iy]erDieser Ausdruck passt auf vier verschiedene Schreibweisen des häufigen deutschen Familiennamens. Dem großen M kann ein kleines "a" oder ein kleines "e" folgen, dann muss ein "i" oder "y" folgen, zum Abschluss dann "er".
Anmerkung für Fortgeschrittene:
Reguläre Ausdrücke können mit sogenannten endlichen Automaten akzeptiert werden: Ein endlicher Automat zum Akzeptieren der Meyer/Meier/Mayer/Maier-Varianten sähe wohl so aus:
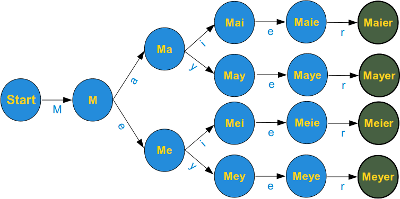
Vereinfachung im Diagramm: Eigentlich müsste es im Startknoten einen Zeiger geben, der wieder auf den Startknoten zurückzeigt. Das heißt, man bleibt solange auf dem Startknoten, wie man Zeichen ließt, die von "M" verschieden sind. Von allen andern Knoten müsste es auch einen Pfeil zum Startknoten zurück geben, wenn man kein Zeichen liest, was auf den ausgehenden Pfeilen vorhanden ist. Wie bereits eingangs gesagt, kann man das eben über endliche Automaten gesagte getrost ignorieren, wenn man es nicht versteht. Es ist nicht wesentlich für die Anwendung von regulären Ausdrücken.
Statt einzelner Buchstaben, wie im vorigen Beispiel die Auswahl zwischen "e" oder "a" (in RE-Notation [ea]), benötigt man sehr häufig die Auswahl zwischen ganzen Zeichenklassen, also zum Beispiel eine Ziffer zwischen "0" und "5" oder eine Buchstabe zwischen "a" und "e". Dafür gibt es bei der Notation für reguläre Ausdrücke ein reserviertes Sonderzeichen innerhalb der Zeichenauswahl, nämlich den Bindestrich "-".
[a-e] ist eine abgekürzte Schreibweise für [abcde] oder [0-5] steht
für [012345].
Der Vorteil beim Schreiben wird sofort ersichtlich, wenn man die Zeichenauswahl "ein beliebiger Großbuchstabe"
notieren will. Man kann
[ABCDEFGHIJKLMNOPQRSTUVWXYZ] oder [A-Z] schreiben. Wen das noch nicht überzeugt: Wie sieht
es mit der Zeichenauswahl "ein beliebiger Klein- oder Großbuchstabe" aus?
[A-Za-z]Die umständliche Alternative überlassen wir der geneigten Leserin oder Leser :-)
Aber es gibt noch eine Besonderheit mit dem Bindestrich, den wir benutzt hatten, um den Anfang und das Ende einer Zeichenklasse zu markieren. Der Bindestrich hat nur eine Sonderbedeutung, wenn er innerhalb von eckigen Klammern steht und auch dann nur, wenn er nicht unmittelbar nach der öffnenden eckigen Klammer oder vor der schließenden eckigen Klammer positioniert ist.
So bezeichnet der Ausdruck
[-az] nur die Auswahl zwischen den drei Zeichen "-", "a" und "z",
Aber keine anderen Zeichen. Das gleiche gilt für [az-].
Übung:
Welche Zeichenklasse wird durch
[-a-z] beschrieben?
Antwort Das Zeichen "-", weil es am Anfang direkt nach der öffnenden Klammer steht, und alle Zeichen zwischen "a" bis "z", also das ganze Alphabet der kleinen Buchstaben und der Bindestrich.
Das einzige andere Metazeichen innerhalb von eckigen Klammern ist das Caret-Zeichen (auch Textcursor oder Einschaltungszeichen genannt). Wenn es direkt hinter der öffnenden eckigen Klammer positioniert ist, dann negiert es die Auswahl. Alternativ dazu kann man statt des Caret auch ein Ausrufezeichen zur Negation verwenden.
[^0-9] bezeichnet die Auswahl "irgendein Zeichen aber keine Ziffer".
Die Position des Caret-Zeichen innerhalb der eckigen Klammern ist entscheidend. Wenn es nicht als erstes Zeichen
steht, dann hat es keine spezielle Bedeutung und bezeichnet nur sich selbst.
[^abc] bedeutet alles außer "a", "b" oder "c"
[a^bc] bedeutet entweder ein "a", "b", "c" oder ein "^"
Vordefinierte Zeichenklassen
Übersicht
Aber auch mit der Vereinfachung durch den Bindestrich, also der Angabe von Bereichen, kann es sehr mühsam werden, bestimmte Zeichenklassen auf die bisherige Art und Weise zu konstruieren. Ein gutes Beispiel hierfür ist sicherlich die Zeichenklasse, die einen gültigen Wortbuchstaben definiert. Dies sind alle Klein- und Großbuchstaben, alle Ziffern und der Unterstrich "_". Das entspricht der folgenden Zeichenklasser"[a-zA-Z0-9_]"
Deshalb gibt es für häufig vorkommende Zeichenklassen vordefinierte Kürzel:
| \d | Eine Ziffer, entspricht [0-9]. |
| \D | das Komplement von \d. Also alle Zeichen außer den Ziffern, entspricht der Klassennotation [^0-9]. |
| \s | Ein Whitespace, also Leerzeichen, Tabs, Newlines und so weiter, entspricht der Klasse [ \t\n\r\f\v]. |
| \S | Das Komplement von \s. Also alles außer Whitespace, entspricht [^ \t\n\r\f\v]. |
| \w | Alphanumerisches Zeichen plus Unterstrich, also [a-zA-Z0-9_]. Wenn die LOCALE gesetzt ist, matched es auch noch die speziellen Zeichen der LOCALE, also z.B. die Umlaute. |
| \W | Das Komplement von \w. |
| \b | Passt auf den leeren String, aber nur, wenn dieser am Anfang oder Ende eines Strings ist. |
| \B | Passt wie \b den leeren String, aber nur, wenn dieser nicht am Anfang oder Ende eines Strings ist. |
| \\ | Ein Backslash. |
Wortbegrenzer
Die vordefinierten Zeichenklassen \b und \B der vorigen Übersicht werden häufig nicht richtig verstanden oder gar falsch verstanden. Während die anderen Klassen einzelne Zeichen matchen, - so matcht beispielsweise \w unter anderem "a", "b", "m", "3" und so weiter, - \b und \B matchen aber keine Zeichen. Sie matchen "Positionen" oder "leere Strings" zwischen Zeichen. Ob ein \b oder ein \B matcht hängt vom linken und rechten Nachbarn ab, d.h. es hängt davon ab, welches Zeichen vor und nach dem "leeren String" steht. \b matcht zwischen einem \W- und einem \w-Zeichen oder umgekehrt, wenn er zwischen \w und \W steht. In anderen Worten: \b bezeichnet das Anfang und das Ende eines Wortes, weshalb dieses Metazeichen auch häufig als Wortbegrenzer bezeichnet wird. \B bezeichnet wie üblich, das Komplement, das bedeutet es werden leere Strings zwischen \W und \W und leere Strings zwischen \w und \w gematcht.Wir illustrieren diesen Sachverhalt im folgenden Diagramm:
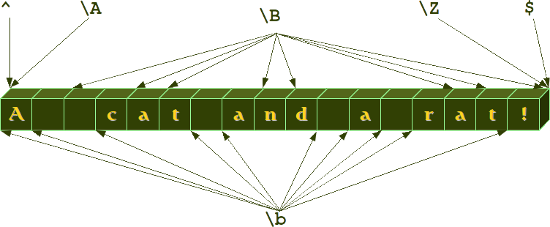
Im folgenden Abschnitt werden wir weitere solche "virtuellen" Zeichen kennenlernen, das Einfügezeichen (^) zur Bezeichnung des Anfangs einer Zeichenkette und das Dollarzeichen ($) zur Bezeichnung des Endes. In dem obigen Diagramm sind auch die sehr selten verwendeten Alternativen für das Einfüge- und Dollarzeichen angegeben, nämlich das \A und das \Z.
Match auf Anfang und Ende
Wie wir bereits ausgeführt hatten, ist der Ausdruckr"M[ae][iy]er" in der Lage verschiedene Schreibweisen
des Namen Meyer zu matchen. Dabei spielt es keine Rolle ob sich der Name am Anfang, im Inneren oder am Ende des
Strings befindet.
>>> import re
>>> line = "Er ist deutsch und wird Mayer genannt."
>>> if re.search(r"M[ae][iy]er",line): print("Treffer!")
...
Treffer!
>>>
Aber wie sieht es aus, wenn wir nur Vorkommen direkt am Anfang des Strings suchen, d.h. dass der String unmittelbar
mit dem "M" des Namens beginnt?
Das re-Modul von Python stellt zwei Funktionen zum Matchen von regulären Ausdrücken zur Verfügung. Eine der beiden haben wir bereits kennengelernt, nämlich die Funktion search(). Die andere Funktion hat unserer Meinung nach einen irreführenden Namen, denn sie heißt match().
Irreführend deshalb, weil match(re_str, s) nur prüft ob eine Übereinstimmung am Anfang des String vorliegt.
Aber egal wie, match() ist eine Lösung auf unsere Fragestellung, wie wir im folgenden Beispiel sehen:
>>> import re >>> s1 = "Mayer ist ein verbreiteter Name" >>> s2 = "Er heißt Mayer, ist aber nicht Deutscher." >>> print(re.search(r"M[ae][iy]er", s1)) <_sre.SRE_Match object; span=(0, 5), match='Mayer'> >>> print(re.search(r"M[ae][iy]er", s2)) <_sre.SRE_Match object; span=(9, 14), match='Meyer'> >>> print(re.match(r"M[ae][iy]er", s1)) <_sre.SRE_Match object; span=(0, 5), match='Mayer'> >>> print(re.match(r"M[ae][iy]er", s2)) None >>>Auf diese Art können wir zwar den Anfang eines Strings matchen, aber diese Methode funktioniert nur in Python. Die Syntax der regulären Ausdrücke stellt uns jedoch eine andere Möglichkeit zur Verfügung.
Das Zeichen '^' (Textcursor, Einfügezeichen) stellt sicher, dass der nachfolgende reguläre Ausdruck nur direkt auf den Anfang des Strings angewendet wird, d.h. der reguläre Ausdruck mit einem führenden "^" muss also auf den Anfang des Strings passen. Außer im MULTILINE-Modus, dann kann der Ausdruck immer auf ein Newline-Zeichen folgen.
>>> import re >>> s1 = "Mayer ist ein verbreiteter Name" >>> s2 = "Er heißt Mayer, ist aber nicht Deutscher." >>> print(re.search(r"^M[ae][iy]er", s1)) <_sre.SRE_Match object; span=(0, 5), match='Mayer'> >>> print(re.search(r"^M[ae][iy]er", s2)) NoneAber was passiert, wenn wir die beiden Strings s1 und s2 auf nachfolgende Art zusammenfügen:
s = s2 + "\n" + s1Der String beginnt nicht mit einem Maier egal in welcher Schreibweise.
>>> s = s2 + "\n" + s1 >>> print(re.search(r"^M[ae][iy]er", s)) None >>>Der Ausdruck konnte nicht matchen. Aber der Name kommt nach einem Newline-Zeichen vor. Deshalb ändert sich das Ergebnis, wenn wir den MULTILINE-Modus zuschalten:
>>> s = s2 + "\n" + s1 >>> print(re.search(r"^M[ae][iy]er", s, re.MULTILINE)) <_sre.SRE_Match object; span=(40, 45), match='Mayer'> >>> print(re.search(r"^M[ae][iy]er", s, re.M)) <_sre.SRE_Match object; span=(40, 45), match='Mayer'> >>> print(re.match(r"^M[ae][iy]er", s, re.M)) None >>>Das vorige Beispiel zeigt auch, dass der Multiline-Modus keinen Einfluss auf die match-Methode hat. match() prüft nie etwas anderes als den Anfang des Strings unabhängig, ob man sich im Multiline-Modus befindet oder nicht.
Damit haben wir die Prüfung für den Anfang eines Strings erledigt. Die Prüfung, ob ein regulärer Ausdruck auf das Ende eines Strings passt sieht ähnlich aus. Dazu erhält das "$"-Zeichen eine Sonderbedeutung. Wird ein regulärer Ausdruck von einem '$'-Zeichen gefolgt, dann muss der Ausdruck auf das Ende des Strings passen, d.h. es darf kein weiteres Zeichen zwischen dem regulären Ausdruck und dem Newline des Strings stehen. Wir demonstrieren dies im folgenden Beispiel:
>>> print(re.search(r"Python\.$","I like Python.")) <_sre.SRE_Match object; span=(7, 14), match='Python.'> >>> print(re.search(r"Python\.$","He likes Java and Perl.")) None >>> print(re.search(r"Python\.$","I like Python.\nSome prefer Java or Perl.")) None >>> print(re.search(r"Python\.$","I like Python.\nSome prefer Java or Perl.", re.M)) <_sre.SRE_Match object; span=(7, 14), match='Python.'> >>>
Optionale Teile
Falls Sie dachten, dass wir bereits alle Schreibweisen der Namen Mayer und Co. erfasst hätten, dann irrten Sie sich. Es gibt noch weitere Varianten in anderen Schreibweisen in der ganzen Welt, egal ob in Paris oder London. In dieser Schreibweise wurde das "e" fallengelassen. Wir erhalten also noch vier weitere Schreibweisen: ["Mayr", "Meyr", "Meir", "Mair"] zuzüglich unsere alte Menge ["Mayer", "Meyer", "Meier", "Maier"].Wenn wir nun versuchen einen passenden regulären Ausdruck zu konstruieren, fällt uns auf, dass uns noch etwas fehlt. Wie können wir sagen "e kann aber muss nicht vorkommen"? Dafür hat man in der Syntax der regulären Ausdrücke dem Fragezeichen eine Sonderbedeutung verpasst. Der Ausdruck "e?" drückt genau aus, was wir wollen, also "der Buchstabe e kann aber muss nicht vorkommen".
Unser finaler Mayer-Erkenner sieht nun wie folgt aus:
r"M[ae][iy]e?r"Ein Fragezeichen kann auch hinter einer runden Klammer stehen. Dann bedeutet das, dass der komplette Unterausdruck innerhalb der Klammern vorkommen kann aber nicht vorkommen muss. Mit dem folgenden Ausdruck können wir Teilstrings mit "Feb 2011" oder "February 2011" erkennen:
r"Feb(ruary)? 2011"
Quantoren
Mit dem, was wir bisher an syntaktischen Mitteln kennengelernt haben, lassen sich bestimmte Eigenschaften nicht in regulären Ausdrücken abbilden. Beispielsweise benötigt man immer wieder Möglichkeiten darzustellen, dass man bestimmte Teilausdrücke wiederholen will. Eine Form von Wiederholung hatten wir gerade eben kennengelernt, das Fragezeichen. Ein Zeichen oder ein in runden Klammern eingeschlossener Teilausdruck wird entweder einmal oder keinmal "wiederholt".Außerdem hatten wir zu Beginn dieser Einführung einen anderen Quantor kennengelernt, ohne dass wir in besonderer Weise auf ihn eingegangen sind. Es handelte sich um den Stern-Operator. Folgt ein Stern "*" einem Zeichen oder einem Teilausdruck, dann heißt dies, dass dieses Zeichen oder der Teilausdruck keinmal oder beliebig oft vorkommen oder wiederholt werden darf.
r"[0-9]*"Der obige Ausdruck passt auf eine beliebige Folge von Ziffern, aber auch auf den leeren String.
r".*"
Übung:
Schreiben Sie einen regulären Ausdruck, der Strings matched, die mit einer Folge von Ziffer - wenigstens einer - beginnen und von einem Leerzeichen gefolgt werden.
Lösung:
r"^[0-9][0-9]* "
So, Sie haben also das Plus-Zeichen verwendet? Das ist super, aber in diesem Fall haben Sie wohl gemogelt, indem Sie weitergelesen haben, oder Sie wissen bereits mehr über reguläre Ausdrücke, als das, was wir bisher in unserem Kurs behandelt haben :-)
Also dann, wenn wir bereits beim Plus-Operator sind: Mit dem Plus-Operator kann man auf angenehme Art und Weise die vorige Übung lösen. Im Prinzip funktioniert der Plus-Operator wie der Sternchen-Operator, nur dass der Plus-Operator wenigstens ein Vorkommen des Zeichens oder Teilausdruckes verlangt.
Lösung unserer Aufgabe mit dem "+"-Operator:
r"^[0-9]+ "Aber auch mit Plus- und Sternchen-Operator fehlt noch etwas Wichtiges: Wir wollen in bestimmten Situation die exakte Anzahl der Wiederholungen oder eine minimale oder maximale Anzahl von Wiederholungen angeben können. Nehmen wir an, dass wir Adresszeilen von Briefumschlägen in der Schweiz lesen wollen. Also die Zeile, in der die Postleitzahl und der Ortsname steht, d.h. eine vierstellige Postleitzahl gefolgt von einem Leerzeichen und dem Ortsnamen. + bzw. * sind zu unspezifisch für diesen Fall, und die folgende Lösung ist sicherlich zu umständlich:
r"^[0-9][0-9][0-9][0-9] [A-Za-z]+"Glücklicherweise bietet die Syntax der regulären Ausdrücke eine optimale Lösung:
r"^[0-9]{4} [A-Za-z]*"
Nun wollen wir unseren regulären Ausdruck noch weiter verbessern. Nehmen wir an, dass es keine Stadt oder Ort in
der Schweiz gibt, deren Name aus weniger als drei Buchstaben besteht. Diesen Umstand können wir mit [A-Za-z]{3,}
beschreiben. Nun wollen wir auch noch Briefe, die nach Deutschland gehen mit erfassen. Postleitzahlen haben
bekanntlich eine Stelle mehr in Deutschland. [0-9]{4,5} bedeutet, dass wir mindestens 4 Ziffern aber höchstens
5 erwarten:
r"^[0-9]{4,5} [A-Z][a-z]{2,}"
Allgemein gilt:
{min, max}: mindestens min-Mal und höchsten max-Mal.
{, max} ist eine abgekürzte Schreibweise für {0,to} und
{min,} ist eine Abkürzung für "höchstens min-Mal aber keine Beschränkung nach oben"
Ein praktisches Beispiel in Python
Bevor wir mit unserer Einführung fortfahren, möchten wir eine kleine praktische Übung in Python einschieben.Dazu haben wir ein Telefonbuch der Simpsons. Genau, DIE SIMPSONS, die aus der berühmten amerikanischen Serie. In dieser Liste befinden sich Leute, die mit Nachnamen "Neu" heißen. Die selbst auferlegte Aufgabe besteht nun darin, diejenigen Leute zu finden, die den Namen Neu führen und deren Vorname mit einem "J" beginnt. Dazu schreiben wir ein Python-Skript, dass diese Zeile einliest und Zeile für Zeile bearbeitet. Für diejenigen, die Probleme mit dem Verarbeiten von Dateien haben, empfehlen wir unser Kapitel über Dateien:
import re
with open("simpsons_phone_book.txt") as fh:
for line in fh:
if re.search(r"J.*Neu",line):
print(line.rstrip())
Das obige Programm liefert folgende Ergebnisse:
Jack Neu 555-7666 Jeb Neu 555-5543 Jennifer Neu 555-3652Statt die Datei simpsons_phone_book.txt runterzuladen kann man sie auch direkt von der Webseite mittels urlopen aus dem Modul urllib.request runterladen:
import re
from urllib.request import urlopen
with urlopen('https://www.python-course.eu/simpsons_phone_book.txt') as fh:
for line in fh:
# line is a byte string so we transform it to utf-8:
line = line.decode('utf-8').rstrip()
if re.search(r"J.*Neu",line):
print(line)
Gruppierungen und Rückwärtsreferenzen
Ausdrücke lassen sich, wie bereits erklärt, mit runden Klammern "(" und ")" zusammenfassen. Die gefundenen Übereinstimmungen der Gruppierungen werden von Python abgespeichert. Dadurch wird deren Wiederverwendung im gleichen regulären Ausdruck an späterer Stelle ermöglicht. Dies bezeichnet man als Rückwärtsreferenzen (engl. back references). \n (n = 1, 2, 3, ... ) bezeichnet die n-te Gruppierung. Bevor wir jedoch weitermachen mit Rückwärtsreferenzen, wollen wir noch einen Paragraphen über Match-Objekte einfügen, die wir im Folgenden benötigen.Match Objects
Bisher waren wir immer nur daran interessiert, ob ein Ausdruck gepasst hatte oder nicht. Wir nutzten die Tatsache, dass Python oder genauer die Methode re.search() ein Match-Object zurückliefert, wenn der reguläre Ausdruck gepasst hat und ansonsten nur ein None. Uns interessierte bisher nicht, was gepasst hatte, also welcher Teilstring. Eine andere Information wäre, wo der Match im String stattfand, also die Start- und die Endposition.Ein match-object enthält die Methoden group(), span(), start() und end(), die man im folgenden Beispiel im selbsterklärenden Einsatz sieht:
>>> import re
>>> mo = re.search("[0-9]+", "Customer number: 232454, Date: February 12, 2011")
>>> mo.group()
'232454'
>>> mo.span()
(17, 23)
>>> mo.start()
17
>>> mo.end()
23
>>> mo.span()[0]
17
>>> mo.span()[1]
23
>>>
Diese Methoden sind nicht schwierig zu verstehen: span() liefert ein 2er-Tupel zurück, das den Anfangs-
und Endwert des Substrings enthält auf den der reguläre Ausdruck passte. Für den Anfangs- und Endwert gibt
es noch zwei Funktionen start() und end(), wobei gilt, dass span()[0] dem Wert von start() und span()[1] dem
Wert von end() entspricht.Wird group() ohne Argumente aufgerufen, liefert es den Substring zurück, der auf den RE gepasst hat. Ruft man group mit einem Integer-Argument n auf, liefert es den Substring zurück, auf den die n-te Gruppe gepasst hatte. Man kann group() auch mit mehr als einem Integer-Wert aufrufen, z.B. group(n,m). Dann wird kein String zurückgeliefert, sondern ein Tupel mit den Werten von group(n) und group(m). Es gilt also (group(n),group(m)) ist gleich group(n,m):
>>> import re
>>> mo = re.search("([0-9]+).*: (.*)", "Customer number: 232454, Date: February 12, 2011")
>>> mo.group()
'232454, Date: February 12, 2011'
>>> mo.group(1)
'232454'
>>> mo.group(2)
'February 12, 2011'
>>> mo.group(1,2)
('232454', 'February 12, 2011')
>>>
Ein sehr intuitives Beispiel stellt das Lesen von korrespondierenden schließenden Tags von XML oder HTML dar.
In einer Datei (z.B. "tags.txt") steht folgender Inhalt:
<composer>Wolfgang Amadeus Mozart</composer> <author>Samuel Beckett</author> <city>London</city>Wir möchten diesen Text automatisch in folgendes Format umschreiben:
composer: Wolfgang Amadeus Mozart author: Samuel Beckett city: LondonDies lässt sich mittels Python und regulären Ausdrücken mit folgendem Skript realisieren. Der reguläre Ausdruck funktioniert wie folgt: Er versucht erst das Symbol "<" zu finden. Danach liest er eine Gruppe von Kleinbuchstaben bis er auf das Größerzeichen ">" stößt. Alles was zwischen "<" und ">" steht, wird in einer Rückwärtsreferenz (backreference) gespeichert und zwar unter \1. Zuerst enthält \1 den Wert "composer". Nachdem der Ausdruck das erste ">" erreicht hat, wird der reguläre Ausdruck so weiter ausgeführt, als hätte er von Anfang an
"<composer>(.*)</composer>" gelautet.
Das zugehörige Python-Skript:
import re
fh = open("tags.txt")
for i in fh:
res = re.search(r"<([a-z]+)>(.*)</\1>",i)
print(res.group(1) + ": " + res.group(2))
Wenn es mehr als ein Klammerpaar (runde Klammern) innerhalb eines regulären Ausdrucks gibt, dann sind die
Rückwärtsreferenzen in der Reihenfolge der Klammern durchnummeriert: \1, \2, \3, ...
Übung:
Im nächsten Beispiel werden drei Rückwärtsreferenzen benutzt. Gegeben ist eine Telefonliste der Simpsons. Nicht jeder Eintrag enthält eine Telefonnummer, aber wenn eine Telefonnummer existiert, dann steht sie am Anfang des Strings. Dann folgt, getrennt durch ein Leerzeichen, der Nachname. Durch ein Komma getrennt folgen dann Vornamen. Die Liste soll in der folgenden Form ausgegeben werden:
Allison Neu 555-8396 C. Montgomery Burns Lionel Putz 555-5299 Homer Jay Simpson 555-7334Hier nun das Python-Skript, dass das Problem löst:
import re
l = ["555-8396 Neu, Allison",
"Burns, C. Montgomery",
"555-5299 Putz, Lionel",
"555-7334 Simpson, Homer Jay"]
for i in l:
res = re.search(r"([0-9-]*)\s*([A-Za-z]+),\s+(.*)", i)
print(res.group(3) + " " + res.group(2) + " " + res.group(1))
Backreferences mit Namen
Wir sind in den vorangegangenen Unterkapiteln auf "Gruppierungen" und "Rückwärtsreferenzen" eingegangen. Man könnte auch sagen "Nummerierte Gruppierungen" und "Nummerierte Rückwärtsreferenzen". Wenn wir "Gruppierungen" statt "Nummerierte Gruppierungen" verwenden, können eigene Bezeichner verwendet werden anstelle von automatisch generierten Nummern. Mit folgendem Beispiel erläutern wir dieses Verhalten indem wir die Stunden, Minuten und Sekunden aus einem UNIX-Datum-String extrahieren.
>>> import re
>>> s = "Sun Oct 14 13:47:03 CEST 2012"
>>> expr = r"\b(?P<hours>\d\d):(?P<minutes>\d\d):(?P<seconds>\d\d)\b"
>>> x = re.search(expr,s)
>>> x.group('hours')
'13'
>>> x.group('minutes')
'47'
>>> x.start('minutes')
14
>>> x.end('minutes')
16
>>> x.span('seconds')
(17, 19)
>>>
Umfangreiche Python Übung
In dieser umfangreichen Übung müssen wir die Informationen aus zwei Listen mit Hilfe von regulären Ausdrücken zusammenbringen. Die erste Datei beinhaltet nahezu 15000 Zeilen mit Postleitzahlen mit den zugehörigen Städtenamen, sowie weiteren Informationen. Es folgen ein paar willkürlich ausgewählte Zeilen zur Verdeutlichung und zur Benutzung für reguläre Ausdrücke:osm_id ort plz bundesland 1104550 Aach 78267 Baden-Württemberg ... 446465 Freiburg (Elbe) 21729 Niedersachsen 62768 Freiburg im Breisgau 79098 Baden-Württemberg 62768 Freiburg im Breisgau 79100 Baden-Württemberg 62768 Freiburg im Breisgau 79102 Baden-Württemberg ... 454863 Fulda 36037 Hessen 454863 Fulda 36039 Hessen 454863 Fulda 36041 Hessen ... 1451600 Gallin 19258 Mecklenburg-Vorpommern 449887 Gallin-Kuppentin 19386 Mecklenburg-Vorpommern ... 57082 Gärtringen 71116 Baden-Württemberg 1334113 Gartz (Oder) 16307 Brandenburg ... 2791802 Giengen an der Brenz 89522 Baden-Württemberg 2791802 Giengen an der Brenz 89537 Baden-Württemberg ... 1187159 Saarbrücken 66133 Saarland 1256034 Saarburg 54439 Rheinland-Pfalz 1184570 Saarlouis 66740 Saarland 1184566 Saarwellingen 66793 Saarland
Die andere Datei enthält eine Liste der 19 größten deutschen Städte. Jede Zeile enthält die Position der Stadt, den Stadtnamen, die Einwohnerzahl und das Bundesland, aber nicht die Postleitzahl:
1. Berlin 3.382.169 Berlin 2. Hamburg 1.715.392 Hamburg 3. München 1.210.223 Bayern 4. Köln 962.884 Nordrhein-Westfalen 5. Frankfurt am Main 646.550 Hessen 6. Essen 595.243 Nordrhein-Westfalen 7. Dortmund 588.994 Nordrhein-Westfalen 8. Stuttgart 583.874 Baden-Württemberg 9. Düsseldorf 569.364 Nordrhein-Westfalen 10. Bremen 539.403 Bremen 11. Hannover 515.001 Niedersachsen 12. Duisburg 514.915 Nordrhein-Westfalen 13. Leipzig 493.208 Sachsen 14. Nürnberg 488.400 Bayern 15. Dresden 477.807 Sachsen 16. Bochum 391.147 Nordrhein-Westfalen 17. Wuppertal 366.434 Nordrhein-Westfalen 18. Bielefeld 321.758 Nordrhein-Westfalen 19. Mannheim 306.729 Baden-WürttembergDie Aufgabe besteht nun darin die 19 größten Städte zusammen mit Ihren Postleitzahlen auszugeben. Um das nachfolgende Programm in Python zu testen, sollte man die obige Liste in einer Datei namens largest_cities_germany.txt abspeichern und die Liste der deutschen Postleitzahlen herunterladen.
import re
with open("zuordnung_plz_ort.txt", encoding="utf-8") as fh_post_codes:
codes4city = {}
for line in fh_post_codes:
res = re.search(r"[\d ]+([^\d]+[a-z])\s(\d+)", line)
if res:
city, post_code = res.groups()
if city in codes4city:
codes4city[city].add(post_code)
else:
codes4city[city] = {post_code}
with open("largest_cities_germany.txt", encoding="utf-8") as fh_largest_cities:
for line in fh_largest_cities:
re_obj = re.search(r"^[0-9]{1,2}\.\s+([\w\s-]+\w)\s+[0-9]", line)
city = re_obj.group(1)
print(city, codes4city[city])
Die Ausgabe sieht wie folgt aus. Allerdings haben wir nur jeweils die ersten drei Postleitzahlen pro Stadt ausgegeben:
$ python3 largest_cities_postcode.py
Berlin {'10715', '13158', '13187', ...}
München {'80802', '80331', '80807', ...}
Köln {'51065', '50997', '51067', ...}
Frankfurt am Main {'65934', '60529', '60308', ...}
Essen {'45144', '45134', '45309', ... }
Dortmund {'44328', '44263', '44369',...}
Stuttgart {'70174', '70565', '70173', ...}
Düsseldorf {'40217', '40589', '40472', ...}
Bremen {'28207', '28717', '28777', ...}
Hannover {'30169', '30419', '30451', ...}
Duisburg {'47137', '47059', '47228', ...}
Leipzig {'4158', '4329', '4349', ...'}
Nürnberg {'90419', '90451', '90482', ...}
Dresden {'1217', '1169', '1324', ...}
Bochum {'44801', '44892', '44805', ...}
Wuppertal {'42109', '42119', '42287', ...}
Bielefeld {'33613', '33607', '33699', ...}
Mannheim {'68161', '68169', '68167', ...}
Noch ein postalisches Beispiel
Es folgt ein weiteres umfangreiches Beispiel mit regulären Ausdrücken und Python. Diesmal verlassen wir Deutschland und die Schweiz und gehen nach England bzw. genauer gesagt ins Vereinigte Königreich. Wir schreiben einen regulären Ausdruck für einen UK-Postcode.Ein Postcode besteht dort aus fünf oder sieben Zeichen, die durch ein Leerzeichen in zwei Teile gegliedert sind. Die zwei bis vier Zeichen vor dem Leerzeichen stellen den sogenannten Abgangscode (outward code) dar, der dazu dient die Post im Eingangspostamt für die Zielpostämter zu verteilen. Nach dem Leerzeichen folgt eine Ziffer, die von zwei Buchstaben gefolgt wird. Diesen zweiten Teil des Postcodes nennt man den Inward-Code, nach dem im Zielpostamt feinverteilt wird. Die beiden letzten Zeichen können nur aus der Menge ABDHJLNPUWZ sein.
Der Abgangscode, also der erste Teil des Postcodes, hat die folgende Form: Ein oder zwei Großbuchstaben, gefolgt von entweder einer Ziffer oder dem Buchstaben R, optional kann dann noch entweder ein weiterer Buchstabe oder eine weitere Ziffer folgen. (Es gelten noch viele weitere Regeln, welche Buchstaben im Postcode abhängig von Position und Kontext vorkommen können, aber die wollen wir uns hier sparen!)
Es folgt ein regulärer Ausdruck, der eine Obermenge, der gültigen Postcodes aus Großbritannien matched:
r"\b[A-Z]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z]{2}\b"
Das folgende Python-Skript nutzt den obigen Ausdruck:
import re
example_codes = ["SW1A 0AA", # House of Commons
"SW1A 1AA", # Buckingham Palace
"SW1A 2AA", # Downing Street
"BX3 2BB", # Barclays Bank
"DH98 1BT", # British Telecom
"N1 9GU", # Guardian Newspaper
"E98 1TT", # The Times
"TIM E22", # a fake postcode
"A B1 A22", # not a valid postcode
"EC2N 2DB", # Deutsche Bank
"SE9 2UG", # University of Greenwhich
"N1 0UY", # Islington, London
"EC1V 8DS", # Clerkenwell, London
"WC1X 9DT", # WC1X 9DT
"B42 1LG", # Birmingham
"B28 9AD", # Birmingham
"W12 7RJ", # London, BBC News Centre
"BBC 007" # a fake postcode
]
pc_re = r"[A-z]{1,2}[0-9R][0-9A-Z]? [0-9][ABD-HJLNP-UW-Z]{2}"
for postcode in example_codes:
r = re.search(pc_re, postcode)
if r:
print(postcode + " matched!")
else:
print(postcode + " is not a valid postcode!")
Nächstes Kapitel: Reguläre Ausdrücke für Fortgeschrittene