

 Informationen zum Buch
Informationen zum Buch

Sequentielle Datentypen
Einführung

Sequenzen sind neben Zahlen, Zuordnungen, Dateien, Instanzen und Ausnahmen einer der wichtigsten integrierten Datentypen. Python bietet sechs sequenzielle (oder sequentielle) Datentypen:
Zeichenketten (Strings)
Byte-Sequenzen
Byte-Arrays
Listen
Tupel
Entfernungsobjekte
Zeichenfolgen, Listen, Tupel, Bytes und Bereichsobjekte sehen möglicherweise ganz anders aus, haben jedoch noch einige grundlegende Konzepte gemeinsam:
- Die Elemente oder Elemente von Zeichenfolgen, Listen und Tupeln sind in einer definierten Reihenfolge angeordnet.
- Auf die Elemente kann über Indizes zugegriffen werden.
text = "Auf Listen und Strings kann über Indizes zugegriffen werden!"
print(text[0], text[11], text[-2])
Zugriff auf Listen:
lst = ["Wien", "London", "Paris", "Berlin", "Zürich", "Hamburg"]
print(lst[0])
print(lst[2])
print(lst[-1])
Im Gegensatz zu anderen Programmiersprachen verwendet Python die gleichen Syntax- und Funktionsnamen, um sequentielle Datentypen zu bearbeiten. Beispielsweise kann die Länge eines Strings, einer Liste und eines Tupels mit einer Funktion namens len () bestimmt werden:
Länder = ["Deutschland", "Schweiz", "Österreich",
"Frankreich", "Belgien", "Niederlande",
"England"]
len(Länder) # die Länge der Liste; die Anzahl der Objekte
fib = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
len(fib)
s = "Glückliche Fügung"
s_bytes = s.encode('utf-8')
s_bytes
Python-Listen
Bisher haben wir bereits einige Listen verwendet, und hier folgt eine angemessene Einführung. Listen beziehen sich auf Arrays von Programmiersprachen wie C, C ++ oder Java, aber Python-Listen sind weitaus flexibler und leistungsfähiger als "klassische" Arrays. Beispielsweise müssen nicht alle Elemente in einer Liste denselben Typ haben. Darüber hinaus können Listen in einem Programmlauf wachsen, während in C die Größe eines Arrays zur Kompilierungszeit festgelegt werden muss.
Im Allgemeinen ist eine Liste eine Sammlung von Objekten. Genauer gesagt: Eine Liste in Python ist eine geordnete Gruppe von Elementen oder Elementen. Es ist wichtig zu beachten, dass diese Listenelemente nicht vom gleichen Typ sein müssen. Es kann eine beliebige Mischung von Elementen wie Zahlen, Zeichenfolgen, anderen Listen usw. sein. Der Listentyp ist für Python-Skripte und -Programme unerlässlich. Mit anderen Worten, Sie werden ohne Liste kaum ernsthaften Python-Code finden.
Die Haupteigenschaften von Python-Listen:
• Sie sind ordentlich.
• Sie enthalten beliebige Objekte.
• Auf Elemente einer Liste kann über einen Index zugegriffen werden.
• Sie können beliebig verschachtelt werden. Sie können andere Listen als Unterlisten enthalten.
• Variable Größe
• Sie sind veränderlich. Die Elemente einer Liste können geändert werden.
Listennotation und Beispiele
Listenobjekte werden in eckige Klammern eingeschlossen und durch Kommas getrennt. Die folgende Tabelle enthält einige Beispiele für Listen:
| Listen | Beschreibung |
|---|---|
| [] | Eine leere Liste |
| [1, 1, 2, 3, 5, 8] | Eine Liste mit ganzen Zahlen |
| [42, "What's the question?", 3.1415] | Eine Liste mit gemischten Datentypen |
| ["Stuttgart", "Freiburg", "München", "Nürnberg", "Würzburg", "Ulm", "Friedrichshafen", "Zürich", "Wien"] | Eine Liste von Strings |
| [["London", "England", 7556900], ["Paris", "France",2193031], ["Bern", "Switzerland", 123466]] | Eine verschachtelte Liste |
| ["Oberste Ebene", ["Ein Level runter", ["noch tiefer", ["und tiefer", 42]]]] | Eine tief verschachtelte Liste |
Sprachen = ["Python", "C", "C++", "Java", "Perl"]
Es gibt verschiedene Möglichkeiten, auf die Elemente einer Liste zuzugreifen. Der wahrscheinlich einfachste Weg für C-Programmierer sind Indizes. Die Nummern der Listen werden beginnend mit 0 aufgelistet:
Sprachen = ["Python", "C", "C++", "Java", "Perl"]
print(Sprachen[0] + " sind " + Sprachen[1] + " unterschiedlich!")
print("Zugriff auf das letzte Element der Liste: " + Sprachen[-1])
Das vorherige Beispiel einer Liste war eine Liste mit Elementen gleichen Datentyps. Wie wir bereits gesehen haben, können Listen verschiedene Datentypen haben, wie im folgenden Beispiel gezeigt:
Gruppe = ["Bob", 23, "George", 72, "Myriam", 29]
Person = [["Marc", "Mayer"], ["17, Oxford Str", "12345", "London"], "07876-7876"]
Name = Person[0]
print(Name)
Vor_name = Person[0][0]
print(Vor_Name)
Nach_name = Person[0][1]
print(Nach_name)
Adresse = Person[1]
Straße = Person[1][0]
print(Straße)
Das nächste Beispiel zeigt eine komplexere Liste mit einer tief strukturierten Liste:
komplexe_Liste = [["a", ["b", ["c", "x"]]]]
komplexe_Liste = [["a", ["b", ["c", "x"]]], 42]
komplexe_Liste[0][1]
komplexe_Liste[0][1][1][0]
Sprachen = ["Python", "C", "C++", "Java", "Perl"]
Sprachen[4] = "Lisp"
Sprachen
Sprachen.append("Haskell")
Sprachen
Sprachen.insert(1, "Perl")
Sprachen
Einkaufsliste = ['Milch', 'Joghurt', 'Ei', 'Butter', 'Brot', 'Bananen']
Wir gehen in einen virtuellen Supermarkt. Holen Sie sich einen Einkaufswagen und beginnen Sie mit dem Einkauf:
Einkaufsliste = ['Milch', 'Joghurt', 'Ei', 'Butter', 'Brot', 'Bananen']
Einkaufswagen = []
# "pop()"" Entfernt das letzte Element der Liste und gibt es zurück
Artikel = Einkaufsliste.pop()
print(Artikel, Einkaufsliste)
Einkaufswagen.append(Artikel)
print(Einkaufswagen)
# wir machen so weiter:
Artikel = Einkaufsliste.pop()
print("shopping_list:", Einkaufsliste)
Einkaufswagen.append(Artikel)
print("cart: ", Einkaufswagen)
Mit einer while-Schleife:
Einkaufsliste = ['milk', 'yoghurt', 'egg', 'butter', 'bread', 'bananas']
Einkaufswagen = []
while Einkaufsliste != []:
Artikel = Einkaufsliste.pop()
Einkaufswagen.append(Artikel)
print(Artikel, Einkaufsliste, Einkaufswagen)
print("Einkaufsliste: ", Einkaufsliste)
print("Einkaufswagen: ", Einkaufswagen)
Tupel
Ein Tupel ist eine unveränderliche Liste, d. H. Ein Tupel kann nach seiner Erstellung in keiner Weise geändert werden. Ein Tupel wird analog zu Listen definiert, mit der Ausnahme, dass die Elementmenge in Klammern anstelle von eckigen Klammern steht. Die Regeln für Indizes sind dieselben wie für Listen. Sobald ein Tupel erstellt wurde, können Sie einem Tupel keine Elemente hinzufügen oder Elemente aus einem Tupel entfernen.
Wo ist der Nutzen von Tupeln?
• Tupel sind schneller als Listen.
• Wenn Sie wissen, dass einige Daten nicht geändert werden müssen, sollten Sie Tupel anstelle von Listen verwenden, da dies Ihre Daten vor versehentlichen Änderungen schützt.
• Der Hauptvorteil von Tupeln besteht darin, dass Tupel als Schlüssel in Wörterbüchern verwendet werden können, Listen jedoch nicht.
Das folgende Beispiel zeigt, wie Sie ein Tupel definieren und auf ein Tupel zugreifen. Außerdem können wir sehen, dass wir einen Fehler auslösen, wenn wir versuchen, einem Element eines Tupels einen neuen Wert zuzuweisen:
t = ("Tupels", "sind", "unveränderlich")
t[0]
t[0] = "Zuordnungen zu Elementen sind nicht möglich"
Ausschneiden / Slicing
In vielen Programmiersprachen kann es ziemlich schwierig sein, einen Teil eines Strings zu schneiden, und noch schwieriger, wenn Sie ein "Subarray" ansprechen möchten. Python macht es mit seinem Slice-Operator sehr einfach. Slicing wird häufig in anderen Sprachen als Funktion mit möglichen Namen wie "Teilstring", "gstr" oder "substr" implementiert.
Jedes Mal, wenn Sie einen Teil eines Strings oder einer Liste in Python extrahieren möchten, sollten Sie den Slice-Operator verwenden. Die Syntax ist einfach. Eigentlich sieht es ein bisschen so aus, als würde man auf ein einzelnes Element mit einem Index zugreifen, aber statt nur einer Zahl haben wir mehr, getrennt durch einen Doppelpunkt ":". Wir haben einen Start- und einen Endindex, einer oder beide fehlen möglicherweise. Es ist am besten, die Funktionsweise von Slice anhand von Beispielen zu untersuchen:
Slogan = "Python ist großartig"
erste_fünf = Slogan[0:5]
erste_fünf
ab_fünf = Slogan[5:]
ab_fünf
eine_Kopie = Slogan[:]
ohne_letzte_fünf = Slogan[0:-5]
ohne_letzte_fünf
Syntaktisch gibt es keinen Unterschied bei Listen. Wir werden mit europäischen Städtenamen zu unserem vorherigen Beispiel zurückkehren:
Städte = ["Wien", "London", "Paris", "Berlin", "Zürich", "Hamburg"]
erste_drei = Städte[0:3]
# oder einfacher:
erste_drei = Städte[:3]
print(erste_drei)
Jetzt extrahieren wir alle Städte außer den letzten beiden, "Zürich" und "Hamburg":
alles_außer_letzte_zwei = Städte[:-2]
print(alles_außer_letzte_zwei)
Das Schneiden funktioniert auch mit drei Argumenten. Wenn das dritte Argument beispielsweise 3 ist, wird nur jedes dritte Element der Liste, Zeichenfolge oder Tupel aus dem Bereich der ersten beiden Argumente verwendet.
Wenn s ein sequentieller Datentyp ist, funktioniert dies folgendermaßen:
s [Anfang: Ende: Schritt]
Die resultierende Sequenz besteht aus folgenden Elementen:
s[Anfang], s[Anfang + 1 * Schritt], ... s[Anfang + i * Schritt] für alle (Anfang + i * Schritt) < end.
Im folgenden Beispiel definieren wir eine Zeichenfolge und drucken jedes dritte Zeichen dieser Zeichenfolge:
Slogan = "Python unter Linux ist großartig"
Slogan[::3]
Die folgende Zeichenfolge, die wie ein Buchstabensalat aussieht, enthält zwei Sätze. Eine davon enthält verdeckte Werbung für meine Python-Kurse in Kanada:
"TPoyrtohnotno ciosu rtshees lianr gTeosrto nCtiot yb yi nB oCdaennasdeao"
Versuchen Sie, den versteckten Satz mit Slicing herauszufinden. Die Lösung besteht aus 2 Schritten!
s = "TPoyrtohnotno ciosu rtshees lianr gTeosrto nCtiot yb yi nB oCdaennasdeao"
print(s)
s[::2]
s[1::2]
Vielleicht interessiert Sie auch, wie wir den String erstellt haben. Sie müssen das Listenverständnis verstehen, um Folgendes zu verstehen:
s = "Toronto is the largest City in Canada"
t = "Python courses in Toronto by Bodenseo"
s = "".join(["".join(x) for x in zip(s,t)])
s

txt = "Hallo Welt"
len(txt)
a = ["Swen", 45, 3.54, "Basel"]
len(a)
Vorname = "Homer"
Nachname = "Simpson"
Name = Vorname + " " + Nachname
print(Name)
So einfach ist das für Listen:
Farben1 = ["rot", "grün","blau"]
Farben2 = ["schwarz", "weiß"]
Farben = Farben1 + Farben2
print(Farben)
Die erweiterte Zuordnung "+ =", die für arithmetische Zuweisungen bekannt ist, funktioniert auch für Sequenzen.
s + = t
ist syntaktisch dasselbe wie:
s = s + t
Aber es ist nur syntaktisch dasselbe. Die Implementierung ist anders: Im ersten Fall muss die linke Seite nur einmal ausgewertet werden. Augment-Zuweisungen können als Optimierung für veränderbare Objekte angewendet werden.
Überprüfen, ob ein Element in der Liste enthalten ist
Es ist einfach zu überprüfen, ob ein Element in einer Sequenz enthalten ist. Zu diesem Zweck können wir den Operator "in" oder "not in" verwenden. Das folgende Beispiel zeigt, wie dieser Operator angewendet werden kann:
abc = ["a","b","c","d","e"]
"a" in abc
"a" not in abc
"e" not in abc
"f" not in abc
Slogan = "Python ist einfach!"
"y" in Slogan
"x" in Slogan
Wiederholungen
Bisher hatten wir einen "+" - Operator für Sequenzen. Es ist auch ein "∗" - Operator verfügbar. Natürlich ist keine "Multiplikation" zwischen zwei Sequenzen möglich. "*" ist für eine Sequenz und eine ganze Zahl definiert, d. h. "s ∗ n" oder "n ∗ s". Es ist eine Art Abkürzung für eine n-fache Verkettung, d.h.
str ∗ 4
ist das gleiche wie
str + str + str + str
Weitere Beispiele:
3 * "xyz-"
"xyz-" * 3
3 * ["a","b","c"]
Die erweiterte Zuordnung für "∗" kann ebenfalls verwendet werden:
s *= n ist dasselbe wie s = s * n.
Die Fallstricke von Wiederholungen
In unseren vorherigen Beispielen haben wir den Wiederholungsoperator auf Zeichenfolgen und flache Listen angewendet. Wir können es auch auf verschachtelte Listen anwenden:
x = ["a","b","c"]
y = [x] * 4
y
y[0][0] = "p"
y
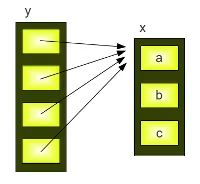
Dieses Ergebnis ist für Anfänger der Python-Programmierung ziemlich erstaunlich. Wir haben dem ersten Element der ersten Unterliste von y einen neuen Wert zugewiesen, dh y [0] [0], und wir haben die ersten Elemente aller Unterlisten in y "automatisch" geändert, dh y [1] [0]. , y [2] [0], y [3] [0].
Der Grund ist, dass der Wiederholungsoperator * 4 4 Verweise auf die Liste x erstellt: und es ist daher klar, dass jedes Element von y geändert wird, wenn wir einen neuen Wert auf y [0] [0] anwenden.