

 Informationen zum Buch
Informationen zum Buch
Arbeiten mit Python, XML and SAX
Vorbemerkung
Dieses Kapitel ist gerade erst im Entstehen, deshalb ist es noch unvollständig und gegebenenfalls fehlerhaft. Also Benutzung auf eigene Gefahr :-=Stand 17. März 2014
Einführung
 XML steht für "Extensible Markup Language" (in Deutsch "erweiterbare Auszeichnungssprache"). Bei XML handelt es sich um eine Auszeichnungssprache zur Darstellung hierarchisch strukturierter Daten in Form von Textdateien. XML eignet sich besonders für den plattform- und implementationsunabhängigen Austausch von Daten zwischen Computersystemen.
XML steht für "Extensible Markup Language" (in Deutsch "erweiterbare Auszeichnungssprache"). Bei XML handelt es sich um eine Auszeichnungssprache zur Darstellung hierarchisch strukturierter Daten in Form von Textdateien. XML eignet sich besonders für den plattform- und implementationsunabhängigen Austausch von Daten zwischen Computersystemen.
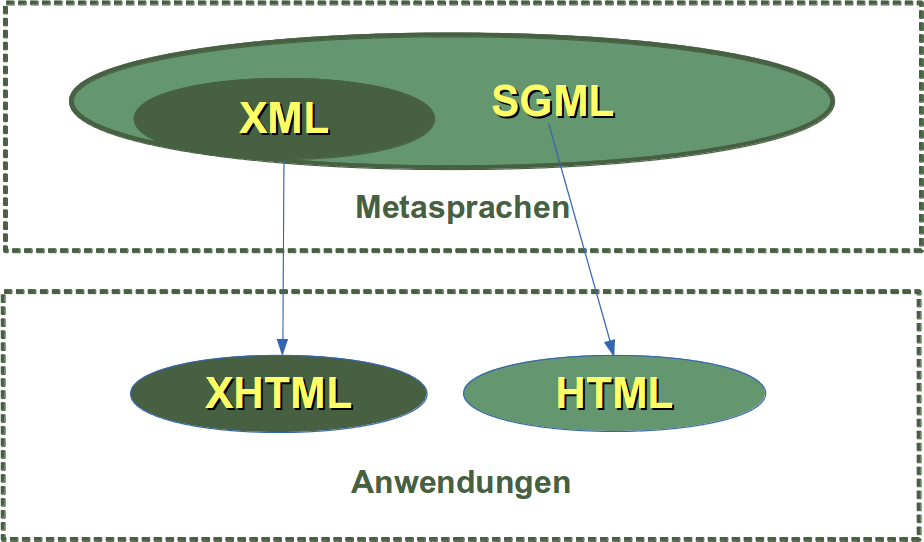
XML seinerseits basiert auf der Metasprache SGML, was für "Standard Generalized Markup Language" (deutsch: Normierte Verallgemeinerte Auszeichnungssprache)
Nicht nur XML sondern auch HTML sind Sprachen, die auf SGML basieren. HTML könnte man als einen für Webseiten optimierten Dialekt von SGML bezeichnen. Während HTML eine Anwendung von SGML ist, bildet XML eine Untermenge von SGML, d.h. alle XML-Dokumente sind konforme SGML-Dokumente. Man könnte XML auch als eine Weiterentwicklung von SGML ansehen.
Vorteile von XML: (Gilt natürlich auch für andere Markup-Sprachen)
- Produktivitätssteigerung im Unternehmen
- Wiederverwendbarkeit der Daten
- Verbesserte Datenintegrität
- Langlebigkeit der Daten
- Verbesserte Datenkontrolle
- Problemloser Datenaustausch
(vor allem auch in heterogenen Systeme) - Flexible Datenausgabe
Arbeitsweise des SAX
Ein SAX-Parser liest XML-Dateien als Datenstrom und ruft für im Standard definierte Ereignisse bestimmte Rückruffunktionen (callback functions) auf.Eine Anwendung kann mit eigenen Rückruffunktionen die Auswertung der XML-Daten beeinflussen.
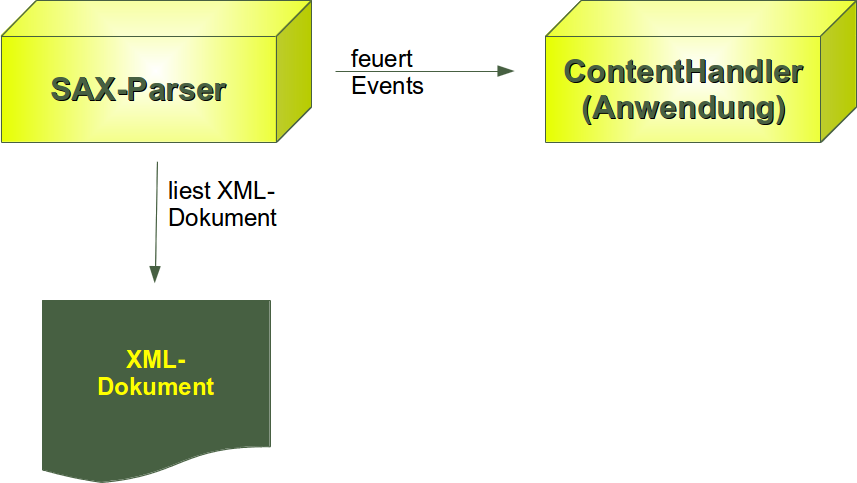
Callback-Methoden im Überblick
In unseren Beispielen haben wir bereits die Methoden "startElement" und "endElement" kennengelernt. Wir haben gesehen, dass sie automatisch vom Sax aufgerufen wurden, wenn diese auf ein Start- bzw. End-Tag gestoßen ist. Methoden dieser Art nennt man Callback-Methoden. Im folgenden finden Sie eine Übersicht über die von SAX verwendeten Callback-Methoden:| Callback-Methode | Erklärung |
|---|---|
| setDocumentLocator (locator) | Aufruf zu Beginn des Parsings. Initialisiert den Locator, der jeweils auf die Position im XML-Dokument verweist, an der sich der Parser gerade befindet. |
| startDocument() | Aufruf beim Beginn des Parsing-Prozesses |
| endDocument() | Aufruf am Ende der Verarbeitung oder nach einem Fehler der zum Abbruch führt. |
| startPrefixMapping (prefix, uri) | Aufruf beim Start eines Elementes, welches ein Namensraum-Präfix besitzt |
| endPrefixMapping (String prefix) | Aufruf beim Abschluss eines Elementes, welches ein Namensraum-Präfix besitzt |
| startElement (name, attrs) | Wird bei jedem öffnenden Tag aufgerufen mit dem Tag-Namen des Elementes "name" und ein Python-Dictionary "attrs" mit den Attributen. |
| endElement (name) | ird bei jedem schließenden Tag aufgerufen mit dem Tag-Namen des Elementes "name" und ein Python-Dictionary "attrs" mit den Attributen. |
| ignorableWhitespace (whitespace) | Die Methode ignorableWhitespace dient zur Behandlung der Whitespace Zeichen zwischen den Elementen. Leerzeichen wie Zeilenumbrüche und Tabs zwischen den Elementen werden normalerweise ignoriert. Die Methode ignorableWhitespace kann zur Behandlung dieser Zeichen verwendet werden. Der Parameter whitespace enthält den gefundenen Leerraum. |
| characters (content) | Gibt den Text zwischen den Markup-Abschnitten zurück. Der Parameter content enthält den tatsächlich gefundenen Leerraum. |
| processingInstruction(target, data) | Reagiert auf Steueranweisungen im Dokument, aber nicht auf die <?xml?>-Steueranweisung am Dokumentbeginn. |
| skippedEntity(name) | Reicht alle Entity-Referenzen an den ContentHandler durch, die nicht vom Parser aufgelöst werden können. |
Das SAX-API definiert vier grundlegende Interfaces. Diese sind in Python als Klassen implementiert:
| Klasse | Erklärung |
|---|---|
| ContentHandler | implementiert das Hauptinterface für Dokumenten-Ereignissen (events) |
| DTDHandler | zum Bearbeiten von DTD-Ereignissen |
| EntityResolver | Klasse zum Auflösen von externen Entitäten |
| ErrorHandler | Klasse zur Behandlung von Fehlern und Warnungen |
Einfaches Beispiel mit SAX
Für die folgenden Beispiele wollen wir die folgende XML-Datei mit Informationen zu Büchern verwenden, die wir unter buecher.xml abspeichern:<?xml version="1.0"?> <bookstore> <book lang="en"> <title>The Language Instinct: How the Mind Creates Language (P.S.)</title> <author>Steven Pinker</author> <price>7.50</price> </book> <book lang="de"> <title>Das unbeschriebene Blatt: Die moderne Leugnung der menschlichen Natur</title> <author>Steven Pinker</author> <price>29.80</price> </book> <book lang="en"> <title>The Black Swan: The Impact of the Highly Improbable</title> <author>Nassim Nicholas Taleb</author> <price>8.10</price> </book> <book lang="fr"> <title>L'Etranger</title> <author>Albert Camus</author> <price>6.10</price> </book> <book lang="de"> <title>Einführung in Python 3</title> <author>Bernd Klein</author> <price>24.99</price> </book> <book lang="de"> <title>Etrusker AG</title> <author>Bernd Klein</author> <price>19.99</price> </book> <book lang="de"> <title>Evariste Galois oder das tragische Scheitern eines Genies</title> <author>Bernd Klein</author> <price>9.99</price> </book> </bookstore>Zuerst wollen wir diese Datei mit SAX scannen und lediglich alle Tags ausgeben. Dazu benötigen wir das SAX-Modul aus dem XML-Paket. Eigentlich benötigen wir nur die beiden Methoden "make_parser" und "handler":
from xml.sax import make_parser, handlerUnser Python-Programm ("buecher.py") zum Scannen der XML-Datei sieht nun wie folgt aus:
from xml.sax import make_parser, handler
class BuecherHandler(handler.ContentHandler):
def startElement(self, name, attrs):
print(name)
parser = make_parser()
b = BuecherHandler()
parser.setContentHandler(b)
parser.parse("buecher.xml")
Wir haben eine Klasse BuecherHandler definiert, die von der Klasse "handler.ContentHandler" erbt. In dieser Klasse überschreiben wir die Methode "startElement". Während der Name der Klasse frei gewählt werden kann, muss die Methode genau diesen Namen und die entsprechende Anzahl der Parameter haben, da es sich ja um die entsprechende Methode von handler.ContentHandler handelt. (Wenn Sie Fragen oder Probleme zum Überschreiben von Methoden und zur Vererbung haben, sollten Sie am besten in unserem Tutorial das Kapitel Vererbung durcharbeiten.)
Der Aufruf "parser = make_parser()" erzeugt ein Parser-Objekt. Dem so generierten Parser "parser" müssen wir mittels der Methode "setContentHandler" eine Instanz b unserer Klasse BuecherHandler() übergeben, die wir mit der Anweisung "b = BuecherHandler()" erzeugt haben. Dann können wir endlich unseren Parser mit "parser.parse("buecher.xml")".
Das XML-Dokument wird nun geparst. Jedesmal, wenn der Parser auf ein Starttag trifft, wird unsere Methode startElement aufgerufen. An den Parameter "name" wird der Name des Tags übergeben und an "attrs" wird ein Objekt mit den Attributen für dieses Tag pbergeben, falls Attribute vorhanden sind. Uns interessiert aber für unser Beispiel nur der Name des Tags.
Die Ausgabe unseres Programms sieht nun wie folgt aus:
$ python3 buecher1.py bookstore book title author price book title author price book title author price book title author price book title author price book title author price book title author priceStatt jeweils sofort den Tagnamen zu drucken, wollen wir nun einfach die Menge der verschiedenen Tags bestimmen. Dazu definieren wir in der nun zu schreibenden Methode "__init__" ein Attribut self.tags, in dem wir die Tagnamen sammeln. Ausserdem benötigen wir eine Methode zur Ausgabe (getTags) der gefundenen Tags:
from xml.sax import make_parser, handler
class BuecherHandler(handler.ContentHandler):
def __init__(self):
self.tags = set()
def startElement(self, name, attrs):
self.tags.add(name)
def getTags(self):
return self.tags
parser = make_parser()
b = BuecherHandler()
parser.setContentHandler(b)
parser.parse("buecher.xml")
print(b.getTags())
Die Ausgabe sieht nun wie folgt aus:
$ python3 buecher1.py
{'price', 'author', 'bookstore', 'book', 'title'}
Nun wollen wir gerne statt der Tagnamen alle Buchtitel und Autoren sammeln:
from xml.sax import make_parser, handler
class BuecherHandler(handler.ContentHandler):
def __init__(self):
self.authors = set()
self.titles = set()
self.current_content = ""
def startElement(self, name, attrs):
self.current_content = ""
def characters(self, content):
self.current_content += content.strip()
def endElement(self, name):
if name == "title":
self.titles.add(self.current_content)
elif name == "author":
self.authors.add(self.current_content)
def getTitles(self):
return self.titles
def getAuthors(self):
return self.authors
parser = make_parser()
b = BuecherHandler()
parser.setContentHandler(b)
parser.parse("buecher.xml")
print("Authors: ")
print(b.getAuthors())
print("Titles:")
print(b.getTitles())
In dem Programm haben wir drei neue Attribute eingeführt: self.authors ist eine Menge, in der wir die Namen der Autoren sammeln. self.titles dient analog für die Buchtitel. self.current_content dient zum Zwischenspeichern der textuellen Information zwischen Start- und End-Tag. Da sich diese Information über mehrere Zeilen erstrecken kann, hängen wir sie mit "+=" an. Wir überschreiben nun auch die Methode endElement, die vom Scanner immer aufgerufen wird, wenn ein Endtag erreicht wird, also z.B. </title> oder </author>. Immer wenn wir ein End-Tag "title" erreichen, addieren wir die Textinformation von self.current_content, also der Titel des Buches, zur Menge self.titles. Entsprechend addieren wir die Textinformation von self.current_content zur Menge self.authors, wenn wir auf einem Endtag "</author>" landen.
Das Programm liefert uns folgende Ausgaben:
$ python3 buecher2.py
Authors:
{'Steven Pinker', 'Nassim Nicholas Taleb', 'Albert Camus', 'Bernd Klein'}
Titles
{'Einführung in Python 3', 'The Language Instinct: How the Mind Creates Language (P.S.)', "L'Etranger", 'Evariste Galois oder das tragische Scheitern eines Genies', 'The Black Swan: The Impact of the Highly Improbable', 'Etrusker AG', 'Das unbeschriebene Blatt: Die moderne Leugnung der menschlichen Natur'}
Schauen wir uns unsere XML-Datei nochmals genommer an, erkennen wir, dass es bei dem Tag "<book>" noch ein Attribut "<lang>" gibt. Im folgenden Programm zeigen wir nun, wie wir auch diese Information erhalten können. In der Methode startElement speichern wir den Wert von "lang" im Instanzattribut self.language, falls das Attribut vorhanden ist. In der Methode endElement hängen wir das Sprachattribut dann an den Titel an:
from xml.sax import make_parser, handler
class BuecherHandler(handler.ContentHandler):
def __init__(self):
self.authors = set()
self.titles = set()
self.current_content = ""
self.language = ""
def startElement(self, name, attrs):
if "lang" in attrs:
self.language = attrs["lang"]
self.current_content = ""
def characters(self, content):
self.current_content += content.strip()
def endElement(self, name):
if name == "title":
txt = self.current_content + " (" + self.language + ")"
self.titles.add(txt)
elif name == "author":
self.authors.add(self.current_content)
def getTitles(self):
return self.titles
def getAuthors(self):
return self.authors
parser = make_parser()
b = BuecherHandler()
parser.setContentHandler(b)
parser.parse("buecher.xml")
print("Authors: ")
print(b.getAuthors())
print("Titles")
print(b.getTitles())
Unsere XML-Datei wird dann in folgende Ausgabe gewandelt:
$ python3 buecher2.py
Authors:
{'Steven Pinker', 'Nassim Nicholas Taleb', 'Albert Camus', 'Bernd Klein'}
Titles
{'The Black Swan: The Impact of the Highly Improbable (en)', 'Evariste Galois oder das tragische Scheitern eines Genies (de)', 'Etrusker AG (de)', 'Das unbeschriebene Blatt: Die moderne Leugnung der menschlichen Natur (de)', 'The Language Instinct: How the Mind Creates Language (P.S.) (en)', "L'Etranger (fr)", 'Einführung in Python 3 (de)'}
Noch ein Beispiel für einen SAX-Parser
import sys
from xml.sax import make_parser, handler
class Counter(handler.ContentHandler):
def __init__(self):
self._elems = 0
self._attrs = 0
self._elem_types = {}
self._attr_types = {}
def startElement(self, name, attrs):
self._elems = self._elems + 1
self._attrs = self._attrs + len(attrs)
self._elem_types[name] = self._elem_types.get(name, 0) + 1
for name in attrs.keys():
self._attr_types[name] = self._attr_types.get(name, 0) + 1
def endDocument(self):
print("Es gibt: ", self._elems, "Elemente.")
print("Es gibt: ", self._attrs, "Attribute.")
print("---Element-Typen:")
for pair in self._elem_types.items():
print("%20s %d" % pair)
print("---Attribut-Typen:")
for pair in self._attr_types.items():
print("%20s %d" % pair)
parser = make_parser()
parser.setContentHandler(Counter())
parser.parse(sys.argv[1])
Dieses Programm liest die verschiedenen Typen, die in einem XML-Dokument vorkommen.
Um dieses Programm zu testen, benötigen wir eine XML-Datei. Wir speichern dazu die folgende Datei unter "addresses.xml" ab:
<?xml version="1.0" ?>
<address-book>
<address id="main">
<name>Homer Simpson</name>
<street>
742 Evergreen Terrace
</street>
<zip country="US">90701</zip>
<location>
Springfield
</location>
</address>
<address id="main">
<name>Charles Montgomery Burns</name>
<street>
1000 Mammon Street
</street>
<zip country="US">90701</zip>
<location>
Springfield
</location>
</address>
</address-book>
Rufen wir dieses Programm auf, erhalten wir folgende Ausgaben:
$ python3 sax_bsp.py addresses.xml
Es gibt: 11 Elemente.
Es gibt: 4 Attribute.
---Element-Typen:
address-book 1
address 2
name 2
street 2
zip 2
location 2
---Attribut-Typen:
id 2
country 2
Beispiel: Serienbrief
Nehmen wir an, wir wollen einen Brief an mehrere Adressaten mit gleichem Text verschicken. Die Adresse wollen wir manuell eingeben.Der Text könnte so aussehen:
An Erika Mustermann Heidestrasse 17 51147 Köln Hallo Erika, wir danken Ihnen für Ihre Kontaktaufnahme und bieten ihnen ....Der Name und die Adresse soll durch die jeweils aktuelle Adresse ersetzt werden.
Mit der String-Methode "format", die wir im Tutorial unter Formatierte Ausgabe ausgiebig beschrieben haben, lässt sich dieses Problem elegant lösen. Hilfreich zum weiteren Verständnis könnte auch unser Beitrag zur Parameterübergabe im Tutorial sein, in dem wir auch die Übergabe eines Dictionaries mit doppeltem Sternchen (**) beschreiben. Zur Lösung des obigen Problems erzeugen wir ein Dictionary mit den Daten und führen dies dem format-String zu. Wir zeigen dies zunächst exemplarisch in einem reduzierten Beispiel in der interaktiven Shell:
>>> p = {"vorname":"Erika"}
>>> txt = "Hallo {vorname}"
>>> print(txt.format(**p))
Hallo Erika
>>>
Die Daten wollen wir mittels interaktiver Eingabe vom User des Programmes erfragen. Die Fragen ("question"), sowie die Zuordnung zu der korrespondierenden Variablen ("var_name") definieren wir in einer XML-Datei:
<?xml version="1.0" ?>
<items>
<item>
<var_name>vorname</var_name>
<question>Vorname: </question>
</item>
<item>
<var_name>nachname</var_name>
<question>Familienname:</question>
<condition>True</condition>
</item>
<item>
<var_name>strasse</var_name>
<question>Straße:</question>
</item>
<item>
<var_name>plz</var_name>
<question>Postleitzahl:</question>
<condition><![CDATA[(len(p['plz'])==4) or (len(p['plz'])==5)]]></condition>
</item>
<item>
<var_name>ort</var_name>
<question>Wohnort:</question>
</item>
</items>
Wir können auch Bedingungen mit dem Tag "condition" definieren. So verlangen wir in unserem Beispiel, dass die Postleitzahl nur 4 Stellen (Schweiz und Österreich) oder 5 Stellen (Deutschland) haben dürfen.
Unseren "Serienbrief" formulieren wir nun als Formatstring:
An
{vorname} {nachname}
{strasse}
{plz} {ort}
Hallo {vorname},
wir danken Ihnen für Ihre Kontaktaufnahme und bieten ihnen
....
Jetzt müssen wir "lediglich" noch die XML-Datei parsen und das Dictionary mit den Daten erzeugen.
Für den SAX-Parser definieren wir eine Klasse Questions:
import sys
from xml.sax import make_parser, handler
class Questions(handler.ContentHandler):
def __init__(self):
self.item = {}
self.current_content = ""
self.params = {}
def askQuestion(self):
if "question" in self.item:
answer = input(self.item["question"] + " ")
return answer
def startElement(self, name, attrs):
if name != "items":
self.item[name] = ""
def characters(self, content):
self.current_content += content.strip()
def endElement(self, name):
if name == "item":
value = self.askQuestion()
self.params[self.item["var_name"]] = value
p = self.params
if "condition" in self.item:
if not eval(self.item["condition"]):
print("warning: condition of " + self.item["var_name"] + " not satisfied")
self.item = {}
else:
if name != "items":
self.item[name] = self.current_content
self.current_content = ""
def endDocument(self):
pass
def getParams(self):
return self.params
Im folgenden Programm, das wir unter QaA.py" speichern, parsen wir dann unsere Datei "questions.txt".
import sys
from xml.sax import make_parser, handler
from questions import Questions
from answers import Answers
parser = make_parser()
q = Questions()
parser.setContentHandler(q)
parser.parse("questions.txt")
params = q.getParams()
txt = open("ausgabe_format.txt").read()
txt = txt.format(**params)
print(txt)
Wir erhalten das gewünschte Ergebnis, wenn wir unser Programm mit "python3 QaA.py" starten:
Vorname: Erika Familienname: Mustermann Straße: Musterstraße 42 Postleitzahl: 42424 Wohnort: Musterstadt An Erika Mustermann Musterstraße 42 42424 Musterstadt Hallo Erika, wir danken Ihnen für Ihre Kontaktaufnahme und bieten ihnen ....
In unserem folgenden Beispiel geht es um Währungen und deren Wechselkurse. Wir werden die XML-Datei ">currencies_quote.xml mittels SAX-Parser einlesen und ein Dictionary mit den Wechselkursen erzeugen. (Stand der Kurse: 11. November 2017) Alle Wechselkurse ind relativ zum US-Dollar angegeben. Ein Währungssatz - in unserem Beispiel der kanadische Dollar - sieht wie folgt aus:
In dem SAX-Programm lesen wir nur die Werte von den Tag field ein, falls das Attribut "name" oder "price" gesetzt ist:USD/CAD 1.268100 CAD=X 1510354148 currency 2017-11-10T22:49:08+0000 0
from xml.sax import make_parser, handler
class CurrencyExtractor(handler.ContentHandler):
def __init__(self):
self.currencies = {}
self.flag = None
self.currency = ""
def startElement(self, name, attrs):
if name == "field":
if attrs["name"] == "name":
self.flag = "currency"
elif attrs["name"] == "price":
self.flag = "price"
def characters(self, content):
if self.flag == "currency":
self.flag = None
self.currency = content[4:]
elif self.flag == "price":
self.currencies[self.currency] = content
self.flag = None
parser = make_parser()
extractor = CurrencyExtractor()
parser.setContentHandler(extractor)
res = parser.parse("currencies_quote.xml")
print(extractor.currencies)
{'KRW': '1119.369995', 'ER 1 OZ 999 NY': '0.059259', 'VND': '22702.000000',
'BOB': '6.860000', 'MOP': '8.033700', 'BDT': '83.139999', 'MDL': '17.527000',
'VEF': '9.974500', 'GEL': '2.627000', 'ISK': '103.400002',
'BYR': '20020.000000', 'THB': '33.110001', 'MXV': '3.253987',
'TND': '2.499000', 'JMD': '125.650002', 'DKK': '6.378170',
...
'SAR': '3.749900', 'UYU': '29.170000', 'GBP': '0.758220', 'UZS': '8050.000000',
'GMD': '46.869999', 'AWG': '1.780000', 'MNT': '2448.000000', 'HKD': '7.799700',
'ARS': '17.479000', 'HUX': '267.679993', 'BRX': '3.265500',
'ECS': '25000.000000'}